Previously chat stream iterator wasn't closed when response streaming
for offline chat model threw an exception.
This would require restarting the application. Now application doesn't
hang even if current response generation fails with exception
GPT-4o-mini is cheaper, smarter and can hold more context than
GPT-3.5-turbo. In production, we also default to gpt-4o-mini, so makes
sense to upgrade defaults and tests to work with it
- Background
Llama.cpp allows enforcing response as json object similar to OpenAI
API. Pass expected response format to offline chat models as well.
- Overview
Enforce json output to improve intermediate step performance by
offline chat models. This is especially helpful when working with
smaller models like Phi-3.5-mini and Gemma-2 2B, that do not
consistently respond with structured output, even when requested
- Details
Enforce json response by extract questions, infer output offline
chat actors
- Convert prompts to output json objects when offline chat models
extract document search questions or infer output mode
- Make llama.cpp enforce response as json object
- Result
- Improve all intermediate steps by offline chat actors via json
response enforcement
- Avoid the manual, ad-hoc and flaky output schema enforcement and
simplify the code
This is a more robust way to extract json output requested from
gemma-2 (2B, 9B) models which tend to return json in md codeblocks.
Other models should remain unaffected by this change.
Also removed request to not wrap json in codeblocks from prompts. As
code is doing the unwrapping automatically now, when present
- Allow free tier users to have unlimited chats with default chat model. It'll only be rate-limited and at the same rate as subscribed users
- In the server chat settings, replace the concept of default/summarizer models with default/advanced chat models. Use the advanced models as a default for subscribed users.
- For each `ChatModelOption' configuration, allow the admin to specify a separate value of `max_tokens' for subscribed users. This allows server admins to configure different max token limits for unsubscribed and subscribed users
- Show error message in web app when hit rate limit or other server errors
Currently, the search model config display for admins only shows the id of the search model config, which is not very informative.
The changes enhances the admin console by displaying the name of the search model config (name), as well as the bi-encoder model (bi_encoder) and cross-encoder model (cross_encoder) along the id.
Previously `force' was passed as a query param to the single indexing API. After the recent API updates, it is meant to select the API method to use (PATCH vs PATCH). Converting `force' argument to a bool fixes implementing this new behavior
- Major
- Improve doc search actor performance on vague, random or meta questions
- Pass user's name to document and online search actors prompts
- Minor
- Fix and improve openai chat actor tests
- Remove unused max tokns arg to extract qs func of doc search actor
- Issue
Previously the doc search actor wouldn't extract good search queries
to run on user's documents for broad, vague questions.
- Fix
The updated extract questions prompt shows and tells the doc search
actor on how to deal with such questions
The doc search actor's temperature was also increased to support more
creative/random questions. The previous temp of 0 was meant to
encourage structured json output. But now with json mode, a low temp is
not necessary to get json output
- Use temperature of 0 by default for extract questions offline chat
actor
- Use temperature of 0.2 for send_message_to_model_offline (this is
the default temperature set by llama.cpp)
* Add ability to cycle through the chat history in the chat input on Obsidian (similar to terminal history navigation)
* Add mod key shortcut to cycle through chat history in chat input
* Add shortcut help text in chat input placeholder
---------
Co-authored-by: Debanjum Singh Solanky <debanjum@gmail.com>
### Overview
Support exclude file filter in user search queries
### Details
- All of the exclude file filter terms need to be satisfied
- Any one of the include file filter terms should be satisfied
### Example
- **Search Query**: *what happened yesterday? -file:"tasks.org" -file:"work.md" file:"diary.org" file:"journal.org*
- **Behavior**: Query will try find relevant notes in any of `journal.org` or `diary.org` and not in `tasks.org` and not in `work.md`
### Details
* Add support for exclusion file filters
* Translate file filter to valid Django DB entry filter regex
* Exclude all files when multiple exclude file filter in query
Previously we were applying an "Or" filter, which would exclude any
file mentioned in a query with multiple exclude file filter.
This is not what we naturally mean when we ask excluding a file in a query
* Rename, rearrange, deduplicate and add file filter tests
Closes#728
---------
Co-authored-by: Debanjum Singh Solanky <debanjum@gmail.com>
Previously required the automation page to be refreshed to see updates
to the automation in the edit automation card. This would be seen when
user tries to edit an automation multiple times (without a page refresh)
Previously, the code incorrectly treated all non-nil values as true, leading to
the index being re-indexed with the force flag whenever the user selected to
update the index.
- Pass the new conversation id as kwarg for the scheduled_chat function
- For edit automations, re-use the original conversation id
- Parse images correctly for image automations
- Use color to provide visual feedback when hover, click on feedback
buttons
- Use color to provide visual feedback when hover on speech, copy
buttons click
- Add cooldown period before being able to send feedback on that message again.
Avoids inadvertent multiple consecutive clicks on feedback buttons
- Since the .gitignore will ignore any of the assets in the src/ folder when building the package wheel, we need to output the static assets to another folder just for the python pypi package. Use /compiled for this.
- Auto focus on email input on login screen for smoother login experience
- Use file icon associated with search page results. Improve search bar
- Show logged in user's email in nav menu for context
- Use previous icons with eyes for search, agents and automations items in nav menu
Hierarchical documents like org-mode, markdown have their ancestry
shown in first line. Remove it to show cleaner, deduplicated reference
text from org-mode, markdown files
Utilize chat footer space more efficiently. This is especially useful
on small screens
- Send button is anyway only enabled when there is text in chat input
- Otherwise voice message button is better to show by default
- Remove invalid call to styles.main
- Remove unnecessary top padding above side pane to keep side pane at
consistent position across web app
- Use same pageLayout styles and styling structure on agent like
automation
- Vertically center automation section and page title on it's row
- Fix applying flex vs grid with tailwind
- Remove x axis footer padding on small screens to preserve space,
keep equal spacing between footer items
- Add 1rem margin to buttons to not have overlap in boundary
- Add 1rem y-axis padding to chat footer to not have focus boundary
leave the footer boundary on smaller screens
Installing Khoj as PWA was supported in previous web UX as well. This
just adds link to the existing webmanifest to continue support for
installing Khoj as PWA with new web UX
Previously the rename wasn't updating the chat session title. We'd
have to refresh the page or side pane to get latest chat session names
after rename action.
Previously the footer's right border wasn't visible on small screens
due to usage of w-full
Use mr-1 on send button instead of px-1 on chat input parent to
eualize chat footer buttons spacing
- Show informative toast messages on copy, delete of API keys
- Onle show API keys card in non anonymous mode. API keys aren't
required (and is disabled on server side) in anon mode. Not showing
card at all in anon mode reduces chance of unnecessary confusion
Style profile pircture button on nav menu
- Use primary colored ring around subscribed user profile on nav menu
- Use gray colored ring around non-subscribed user profile on nav menu
- Use upper case initial as profile pic for user with no profile pic
- Click anywhere on nav menu item to trigger action
Previously the actual clickable area was smaller than the width of
the nav menu item
- Move the nav menu into the chat history side panel component, so that they both show up on one line
- Update all pages to use it with the new formatting
- in mobile, present the sidebar button, home button, and profile button evenly centered in the middle
- Pass userConfig from Home as prop to chatBodyData component with
loading state
- Pass loading state of userConfig to allow components to handle
rendering dependent elements once it is loaded
- Move the nav menu into the chat history side panel component, so that they both show up on one line
- Update all pages to use it with the new formatting
- in mobile, present the sidebar button, home button, and profile button evenly centered in the middle
Use updated format for HTTP streamed responses from the Khoj server in the new chat UX
Remove references to the websocket connected field, as websocket use has been deprecated
Otherwise the Khoj's chat response is filling up in between the
streamed message and already rendered references section at the bottom
of the message
Define OnlineContext type to simplify typing online context param
across other interfaces and functions
- There were some state mismatches in configuring a whatsapp number. This commit fixes those issues and uses an external library for phone number validation
- Note that the SSR for next doesn't support rendering on the client-side, so it'll only update it one big chunk
- Fix unique key error in the chatmessage history for incoming messages
- Remove websocket value usage in the chat history side panel
- Remove other websocket code from the chat page
- Why
Profile section and billing section looked too empty (1 card each).
Combining them makes the setting page look more complete. Shows
subscription options early on
- Details
- Made Futurist text orange
- Made Unsubscribe a down button instead of cloud slash
- Updated toast title to subscription
- Improve Futurist trial title and description
- Remove now unnecessary button to Save in Card with dropdown
- Use toast to show success, failure (not working)
- Rename language to search, Move it to features section. Add icon to
the card
- Update references in new and old web client settings
- Arrange new client settings props and add header comments similar to
- config response for code readability
- Add a lot more suggestions cards, improve mobile rendering of suggestion cards, improve alignment of chat input, shift message when starts recording voice, remove dead code
* Converted navigation menu into a dropdown menu
* Moved collapsed side panel menu icons into top row
* Auto refresh when conversation is deleted to update side panel and route back to main page if deletion is on current conversation
* Highlight the current conversation in the side panel
* Dynamic homepage messages with current day and time of day.
* `colorutils` upgraded to have more expansive tailwind color options and dynamic class name generation.
* Converted create agent button alert into shadcn `ToolTip`
* Colored lines and icons for agents in chat window
* Cleaned up border styling in dark mode
* fixed three dot menu in side panel to be more easier to click
* Add the KhojLogo import in the nav menu and use a default user profile icon when not authenticated
* Get rid of custom --box-shadow CSS variable
* Pass the agent metadat through the chat body data in order to style the send button
* Add login to the unauthenticated login view, redirecto to home if conversation history not loaded
* Set a max height for the input text area
* Simplify tailwind class names
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
## Major: Breaking Changes
- Move API endpoints under /configure/<type>/model to /api/model/<type>
- Move API endpoints under /api/configure/content/ to /api/content/
- Accept file deletion requests by clients during sync
- Split /api/v1/index/update into /api/content PUT, PATCH API endpoints
## Minor: Create New API Endpoint
- Create API endpoints to get user content configurations
Related: #852
- Use new form of passing doc references to now passing chat actor
test
- Fix message list generation from conversation logs provided
Strangely the parent conversation_log gets passed down to
message_to_log func when the kwarg is not explicitly specified
Changes for new agents page
- Modernized agent cards
- Responsive design to support mobile users
- Button for users to create their own agents (coming soon)
- Optimized to use tailwind and icon utils
- Side panel added for quick access to conversations
Previous logic was more brittle to break with simple unbalanced
'{' or '}' string present in the event data. This method of trying to
identify valid json obj was fairly brittle. It only allowed json
objects or processed event as raw strings.
Now we buffer chunk until we see our unicode magic delimiter and only
then process it.
This is much less likely to break based on event data and the
delimiter is more tunable if we want to reduce rendering breakage
likelihood further
- Add support for text to speech, speech to text. Add loading and responsive indicators to reflect state.
- When streaming for speech to text, show incremental transcription in the message input field
- When streaming text to speech, and a pause button in the chat message to allow user to stop playback
* V1 of the new automations page
Implemented:
- Shareable
- Editable
- Suggested Cards
- Create new cards
- added side panel new conversation button
- Implement mobile-friendly view for homepage
- Fix issue of new conversations being created when selected agent is changed
- Improve center of the homepage experience
- Fix showing agent during first chat experience
- dark mode gradient updates
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
- Deduplicate code to collect chat telemetry by relying on
end_llm_response event
- Log time to first token and total chat response time for latency
analysis of Khoj as an agent. Not just the latency of the LLM
- Remove duplicate timer in the image generation path
Do not need response generator to stuff compiled references in chat
stream using "### compiled references:" separator.
References are now sent to clients as structured json while streaming
## Overview
- Gemma 2 is a new open model family by Google. They've released a 9B, 29B param model. A 2B model is also expected.
- It performs really well on the Chatbot arena and shows good performance when testing within Khoj as well.
- Llama.cpp support for Gemma 2 architecture seems to have stabilized
- If Gemma 2 performs well in further testing, it can be made the default offline chat model for Khoj
- Once the 2B param model is released, the model size to download can be automatically chosen based on (V)RAM available
## Major
- Support Gemma 2 for Offline Chat
- Improve and fix chat model prompts for better, consistent context
## Minor
- Fix and improve offline chat actor, director tests
- Improve offline chat truncation to consider chat message delimiter tokens
Previously loading animation would be at top of message. Moving it to
bottom is more intuitve and easier to track.
Remove white-space: pre from list elements. It was adding too much y
axis padding to chat messages (and train of thought)
- Details
Only return notes refs, online refs, inferred queries and generated
response in non-streaming mode. Do not return train of throught and
other status messages
Incorporate missing logic from old chat API router into new one.
- Motivation
So we can halve chat API code by getting rid of the duplicate logic
for the websocket router
The deduplicated code:
- Avoids inadvertant logic drift between the 2 routers
- Improves dev velocity
- Overview
Use simpler HTTP Streaming Response to send status messages, alongside
response and references from server to clients via API.
Update web client to use the streamed response to show train of thought,
stream response and render references.
- Motivation
This should allow other Khoj clients to pass auth headers and recieve
Khoj's train of thought messages from server over simple HTTP
streaming API.
It'll also eventually deduplicate chat logic across /websocket and
/chat API endpoints and help maintainability and dev velocity
- Details
- Pass references as a separate streaming message type for simpler
parsing. Remove passing "### compiled references" altogether once
the original /api/chat API is deprecated/merged with the new one
and clients have been updated to consume the references using this
new mechanism
- Save message to conversation even if client disconnects. This is
done by not breaking out of the async iterator that is sending the
llm response. As the save conversation is called at the end of the
iteration
- Handle parsing chunked json responses as a valid json on client.
This requires additional logic on client side but makes the client
more robust to server chunking json response such that each chunk
isn't itself necessarily a valid json.
- Convert functions in SSE API path into async generators using yields
- Validate image generation, online, notes lookup and general paths of
chat request are handled fine by the web client and server API
* Update the automations UI to be a more suitable color distribution based on new designs
* Use accented colors for the metadata, update dark mode colors
* Update form to use icons as well and render more pretty inline form labels
Pull out /api/configure/phone API endpoints into /api/phone for
more concise and sufficiently explanatory API path
Refactor Flow
1. Rename /api/configure/phone -> /api/phone
Now the API to configure all the AI models is under /api/models.
This provides better organization and API hierarchy. The /configure
url segment was redundant.
- Rename POST /api/phone to PATCH /api/phone
- Rename GET /api/configure to GET /api/settings
Refactor Flow
1. Move out POST /user/name to main api.py
2. Rename /api/configure/<type>/model -> /api/model/<type>
3. Rename @api_configure to @api_mode
4. Rename file api_config.py to api_model.py
Pull out /api/configure/content API endpoints into /api/content to
allow for more logical organization of API path hierarchy
This should make the url more succinct and API request intent more
understandable by using existing HTTP method semantics along with the
path.
The /configure URL path segment was either
- redundant (e.g POST /configure/notion) or
- incorrect (e.g GET /configure/files)
Some example of naming improvements:
- GET /configure/types -> GET /content/types
- GET /configure/files -> GET /content/files
- DELETE /configure/files -> DELETE /content/files
This should also align, merge better the the content indexing API
triggered via PUT, PATCH /content
Refactor Flow
1. Rename /api/configure/types -> /api/content/types
2. Rename /api/configure -> /api
3. Move /api/content to api_content from under api_config
- Remove unused full_corpus boolean. The full_corpus=False code path
wasn't being used (accept for in a test)
- The full_corpus=True code path used was ignoring file deletion
requests sent by clients during sync. Unclear why this was done
- Added unit test to prevent regression and show file deletion by
clients during sync not ignored now
- This utilizes PUT, PATCH HTTP method semantics to remove need for
the "regenerate" query param and "/update" url suffix
- This should make the url more succinct and API request intent more
understandable by using existing HTTP method semantics
- Add day of week to system prompt of openai, anthropic, offline chat models
- Pass more context to offline chat system prompt to
- ask follow-up questions
- know where to find information about khoj (itself)
- Fix output mode selection prompt. Log error if model does not select
valid option from list of valid output modes provided
- Use consistent names for question, answers passed to
extract_questions_offline prompt
- Log which model extracts question, what the offline chat model sees
as context. Similar to debug log shown for openai models
- Pass system message as the first user chat message as Gemma 2
doesn't support system messages
- Use gemma-2 chat format
- Pass chat model name to generic, extract questions chat actors
Used to figure out chat template to use for model
For generic chat actor argument was anyway available but not being
passed, which is confusing
### Major
- Reuse get config data logic across config pages on web client
- Make config api endpoint urls and response fields consistent
- Rename API path /api/config to /api/configure
- Move Web, Desktop client settings page to be under `/settings` from the previous `/config` url path
### Minor
- Pass isMobileWidth prop to SidePanel via chat share interface
- Turn prettier off instead of throwing error for now
- Do no explicitly add line-clamp plugin as it's in Tailwind by default
- Update references to the settings page to use new url across docs
and code
- Rename desktop and web settings page to settigns.html instead of
config[ure].html
- Use name, id for every [search|chat|voice|pain]_model_option
- Rename current_model_state field to more intuitive enabled_content_source
- Update references to the update fields in config.html
- Deprecate khoj-assistant pypi package. Use more accurate and
succinct pypi project name, khoj
- Update references to sye khoj pypi package in docs and code instead
of the legacy khoj-assistant pypi package
- Update pypi workflow to publish to both khoj, khoj-assistant for now
- Update stale python 3.9 support mentioned in our pyproject. Can't
support python 3.9 as depend on latest django which support >=3.10
- Put logic to get config data, detailed or basic into router helpers module
- Use the get config func across the config pages on web clients
- Put configure content and get_notion_auth_url funcs in router helper
module to avoid circular import
Migrates the Automations page to React, mostly keeping the overall design consistent with organization. Use component library, with some changes in color. Add easier management with straightforward form and editing experience.
Use system preference for determining dark mode if not explicitly set.
### Behavior
- Close chat sessions side panel on click open a chat session
- Show agent profile card with description when hover on agent in chat view
- Show action bar on last chat message without hover
- Show chat message action buttons without hover on mobile interfaces
- Show chat message timestamp on hover in chat view
- Show text descriptions of chat message action buttons on hover
- Render inline png, webp images generated by Khoj in chat view
### Fixes
- Do not render references with broken links in chat view
- Fix closing side panel on mobile when click open a chat session
- Only open side panel as drawer in mobile view
- Constrain chat messages to stay within view port across screen sizes
### Styling: Spacing, Sizing, Mobile Friendly
- Make Khoj icon appropriately sized and side panel arrow bold
- Conversations list should resize to take max space on side panel
- Make loading message, styling configurable. Do not show agent when no data
- Improve Train of Thought icons spacing and loading circle
- Improve mobile friendly styling of chat session side panel
- Improve styling of chat input, references UI across screen sizes
- Center cursor in chat input. See upto 2 lines for multi-line context
### Miscellaneous
- Add code formatter for web interface with prettier
- Updated references panel
- Use subtle coloring for chat cards
- Chat streaming with train of thought
- Side panel with limited sessions, expandable
- Manage conversation file filters easily from the side panel
- Updated nav menu, easily go to agents/automations/profile
- Upload data from the chat UI (on click attachment icon)
- Slash command pop-up menu, scrollable and selectable
- Dark mode-enabled
- Mostly mobile friendly
- Pass Loading message, class name via props to both inline and normal
loading spinners
- Pass loading conversation message to loading spinner when chat
history is being fetched
- Create profile card componennt. Use it for agent profile card
- Pass agent persona from khoj server via API
- Put link to agent profile page in the hover card to make it 2 clicks
away. Othewise inadvertent clicks on agent in chat view lead away to
agent page
- Use tailwind line-clamp extension to clamp card to first two lines
- Reuse class name when get slash command icons
- Previous chat input styling didn't have the cursor centered in the
chat input text area. But it did allow seeing multi line chat inputs
for context
- Major
- Ask for prompt in prose
- Remove seed from SD3 image generation to improve diversity of output
for a given prompt
Otherwise for conversations with similar sounding
prompts, the images would be almost exactly the same. This maybe
another indicator of SD3's inability to capture detailed
instructions
- Consistently use "prompt" wording instead of "query" in improved
image generation prompts.
Previously a mix of those terms were being used, which could confuse
the chat model
- Minor
- Add day of week to prompt
- Remove 2-5 sentence limit on instructions to SD3. It seems to be
able to follow longer instructions just with less fidelity than
DALLE. And the 2-5 sentence instruction limit wasn't being adhered to
- Improve ability to edit, improve the image based on follow-up
instructions by the user
- Align prompts for DALLE and SD3. Only difference is to wrap text to
be rendered in quotes for SD3. This improves it's ability to render
requested text. DALLE cannot render text as well or consistently
- Because we're using a FastAPI api framework with a Django ORM, we're running into some interesting conditions around connection pooling and clean-up. We're ending up with a large pile-up of open, stale connections to the DB recurringly when the server has been running for a while. To mitigate this problem, given starlette and django run in different python threads, add a middleware that will go and call the connection clean up method in each of the threads.
- Issue
The Khoj docker build would fail with `ImportError: libGL.so.1: cannot open shared object file: No such file or directory`. This was required by the Khoj RapidOCR python package dependency.
- Fix
A minimal set of system packages have been added to resolve this issue.
- Transcribe on holding Ctrl+s keyboard shortcut
- Transcribe on holding the transcribe button pressed via mouse too
- Make the transcribe button robust to inadvertent touches by using timeout
- Do not transcribe, trigger auto-send on silences. Silence detection
is super rudimentary, just blocks standard emanations by whisper
when no speech
### Fix
- Fix degrade in speed when indexing large files
- Resolve org-mode indexing bug by splitting current section only once by heading
- Improve summarization by fixing formatting of text in indexed files
### Improve
- Improve scaling user, admin flows to delete all entries for a user
- Split once by heading (=first_non_empty) to extract current section body
Otherwise child headings with same prefix as current heading will
cause the section split to go into infinite loop
- Also add check to prevent getting into recursive loop while trying
to split entry into sub sections
Adding files to the DB for summarization was slow, buggy in two ways:
- We were updating same text of modified files in DB = no of chunks
per file times
- The `" ".join(file_content)' code was breaking each character in the
file content by a space. This formats the original file content
incorrectly before storing in the DB
Because this code ran in the main file indexing path, it was slowing down
file indexing. Knowledge bases with larger files were impacted more strongly
- Delete entries by batch to improve efficiency of query at scale
- Share code to delete all user entries between it's async, sync methods
- Add indicator to show when files being deleted on web config page
- Add CSP to web config pages. Load phone no. validation js, css from S3
- Construct config page elements on Web via DOM scripting
- Disable CSP in Khoj Obsidian as it interferes with Obsidian functionality
- Other miscellaneous voice message level improvements (rate limit, listening animation)
The Khoj CSP interferes with other Obsidian features and plugins as
CSP is applied page wide.
For now chat message sanitization via Dompurify should suffice.
Enable CSP when can scope it to only the Khoj Obsidian plugin.
Maybe better to fallback to non-summarize behavior if summarize intent
is just inferred but we can't actually summarize because the single
file added to conversation isn't satisfied
- Simplify quick jump between Khoj side pane and main editor view using keyboard shortcuts
- Enable voice chat in Obsidian to make interactions with Khoj more seamless
- Overview
Khoj wil be able to do online search out of the box, even for self-hosted users
- Default to Jina search, reader API when no Serper.dev, Olostep API keys
- Run online searches in parallel to process multiple queries faster
- Details
- Jina provides a [reader API](https://github.com/jina-ai/reader) for online search and web page reading
It requires no API key. This provides a good default to enable
online search for self-hosted readers requiring no additional setup.
- Jina search API also returns webpage contents with the results, so
just use those directly when Jina Search API used instead of
trying to read webpages separately. The extract relevant content from
webpage step using a chat model is still used from the
`read_webpage_and_extract_content' func in this case.
- Parse search results from Jina search API into same format as
Serper.dev for accurate rendering of online references by clients
- Run online searches in parallel with AsyncIO to process multiple queries faster
- Support Stable Diffusion 3 via API
Server Admin needs to setup model similar to DALLE-3 via Django Admin Panel
- Use shorter prompt generator to prompt SD3 to create better images
- Allow users to set paint model to use from web client config page
Update offline, openai chat actor, director tests to not require
Serper to run the online command tests
Update documentation for self-hosted online search to mention no setup
is required by default. But improvements can be made by using
Serper.dev or Olostep
Jina AI provides a search and webpage reader API that doesn't require
an API key. This provides a good default to enable online search for
self-hosted readers requiring no additional setup.
Jina search API also returns webpage contents with the results, so
just use those directly when Jina Search API used instead of
trying to read webpages separately. The extract relvant content from
webpage step using a chat model is still used from the
`read_webpage_and_extract_content' func in this case.
Parse search results from Jina search API into same format as
Serper.dev for accurate rendering of online references by clients
- Added support for uploading .jpeg, .jpg, and .png files to Khoj from Web, Desktop app
- Updating indexer to generate raw text and entries using RapidOCR
- Details
* added support for indexing images via ocr
* fixed pyproject.toml
* Update src/khoj/processor/content/images/image_to_entries.py
Co-authored-by: Debanjum <debanjum@gmail.com>
* Update src/khoj/processor/content/images/image_to_entries.py
Co-authored-by: Debanjum <debanjum@gmail.com>
* removed redudant try except blocks
* updated desktop js file to support image formats
* added tests for jpg and png
* Fix processing for image to entries files
* Update unit tests with working image indexer
* Change png test from version verificaition to open-cv verification
---------
Co-authored-by: Debanjum <debanjum@gmail.com>
Co-authored-by: sabaimran <narmiabas@gmail.com>
This should improve fluidity of keyboard interactions with Khoj on
Obsidian.
Open Khoj chat view via keybinding or command pallete and ask
question using only the keyboard, with no mouse clicks required
- Automatically carry out voice chats with Khoj from within Obsidian
When send voice message, Khoj will auto respond with voice as well
- Listen to past Khoj messages as speech
- Add circular loading spinner to use while message is being converted
to speech
* Add a leader election mechanism to circumvent runtime issues for multiple schedulers
- Reduce the load on the DB and risk of issues on the service side by limiting the execution environment to one elected leader at a given time. This one is responsible for managing all of the execution of the jobs, though all workers are capable of adding and removing jobs
* Set a max duration for the schedule leader position (12 hrs), add some error if automation not added successfully
* rough sketch of desktop shortcuts. many bugs to fix still
* working MVP of desktop shortcut khoj
* UI fixes
* UI improvements for editable shortcut message
* major rendering fix to prevent clipboard text from getting lost
* UI improvements and bug fixes
* UI upgrades: custom top bar, edit sent message and color matching
* removed debug javascript file
* font reverted to Noto Sans
* cleaning up the code and removing diffs
* UX fixes
* cleaning up unused methods from html
* front end for button to send user back to main window to continue conversation
* UX fix for window and continue conversation support added
* migrated common js functions into chatutils.js
* Fix window closing issue in macos by
1. Use a helper function to determine if the window is open by seeing if there's a browser window with shortcut.html loaded
2. Use the event listener on the window to handle teardown
* removed extra comment and renamed continue convo button
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
- Add an experimental feature used for fact-checking falsifiable statements with customizable models. See attached screenshot for example. Once you input a statement that needs to be fact-checked, Khoj goes on a research spree to verify or refute it.
- Integrate frontend libraries for [Tailwind](https://tailwindcss.com/) and [ShadCN](https://ui.shadcn.com/) for easier UI development. Update corresponding styling for some existing UI components.
- Add component for model selection
- Add backend support for sharing arbitrary packets of data that will be consumed by specific front-end views in shareable scenarios
Initialize our migration to use Next.js for front-end views via Agents. This includes setup for getting authenticated users, reading in available agents, setting up a pop-up modal when you're clicking on an agent, and allowing users to start new conversations with agents.
Best attempt at an in-place migration, though there are some noticeable differences.
Also adds view for chat that are not being used, but in experimental phase.
Previously the text_to_image helper would only trigger the image
generation flow if OpenAI client was setup. This is not required
anymore as offline chat model + sd3 API works. So remove that check
- Add instructions for self-hosted users with info, warning boxes to
avoid, fix common issues when setting up Khoj server
- Create new Advanced Self Hosting section
- Extract Advanced Self-Hosting Sections from the Advanced Page and
move them to separate Pages under Advanced Self Hosting section
- Improve OpenAI Proxy Docs
- Put Ollama setup as a section under OpenAI API Proxy page instead
of a separate page
- Add Section to use Khoj with chat model from LM Studio
- Update LiteLLM docs to use chat model from LM Studio
This handles updates from manifest.json minAppVersion field to the
versions.json file.
The minAppVersion field is for the minimum Obsidian app version
supported by a Khoj plugin version
Khoj will find and display notes similar to the current entry in the side pane when
1. find similar is open in side pane and
2. cursor has moved to a new entry
### Major
- Find similar notes to current note at cursor automatically in background
- Only show headings of search result and increase default results count
### Minor
- Pass absolute path of file to index from khoj.el emacs client
- Update help message to only show the smaller set of new keybindings
- Fix edge cases in loading some chat sessions
To improve the developer experience for front-end development, we're migrating to Next.js. In order to do this migration page-by-page, we're using static site generation via Next.js. This also helps us avoid making cross site requests from front-end to back-end for the time being, while giving a ramp to separating out server and client if needed for scale down the road.
Dev instructions for using the next.js setup are in the added README.
This adds scaffolding for including the built files in the python package as well as the docker images. Docker setup has been tested locally. In order to verify the build is working as expected, we can navigate to the {khoj_host}:42110/experimental and verify that the experiment page comes up.
This setup works with serving static files included in the src/interface/web folder from the Django app. The key bit for understanding the setup is in the yarn export command in package.json.
- Just use in-built `npm version' command to update desktop, obsidian version
- Upgrade by major, minor or patch version using new -t flag in script
E.g bump_version -t minor
* Enable speech to text responses in khoj chat
- Current issue: reads out all the markdown formatting, plus waits for the whole result to be streamed before playing it
* Extract content from markdown-formatted text
* Add a loader for while you're waiting for Khoj's response
* Add user configuration option for chat model options, allow server side configuration for option list
* Join up APIs, views, admin pages to allow configuring custom voice models
When create new conversation session, automatically request query. As
that is expected next action after creating new session
Pass session-id to khoj-chat to allow reuse from
create-new-conversation func
When delete conversation session, do not call load chat session.
Unnecessary action.
Use thread-last to improve code flow in new, delete conversation funcs
* Add magic link email sign-in option
* Adding backend routes and model changes to keep state of email verification code and status
* Test and fix end to end email verification flow
* Add documentation for how to use the magic link sign-in when self-hosting Khoj
* Add magic link sign in to public conversation page
Previously the cursor would move to the Khoj side pane on opening it.
This would break user's flow, especially when find similar triggers
automatically
New behavior maintains smoother update of auto find similar without
disrupting user browsing
Previously it would show complete result body this would make the
result width variable and hard to track all the returned results
Showing just heading makes it easier to track
- Call find similar on current element if point has moved to new
element
- Delete the first result from find-similar search results as that'll
be the current note (which is trivially most similar to itself)
- Determine find-similar based text formating at the rendering layer
rather than at the top level find-similar func
* Uses entire file text and summarizer model to generate document summary.
* Uses the contents of the user's query to create a tailored summary.
* Integrates with File Filters #788 for a better UX.
To add multiple allowed Khoj domains pass them as a comma separated
list of domains via the KHOJ_DOMAIN environment variable
Resolve comment in issue #662
Given img src enforcement via CSP required loosening. Soft enforce it
via a regex replace of img HTML elements if the src isn't from the
whitelisted set of source prefixes.
Currently allowed source prefixes are
- app: for local images
- data: for inline generated images
- https://generated.khoj.dev: for cloud generated images
- Create and use a function to convert markdown to sanitized html
- Remove unused Latex delimiter handling as Katex isn't used in
Khoj chat on Obsidian
- Open Khoj in Emacs Side pane
Open Khoj chat, search in right pane to allow for ambient engagement
- Improve Khoj Chat
- Show online references used for chat
- Make chat API call async to not block user interactions
- Fix loading chat history, references in khoj.el chat buffer
- Improve Khoj Search, Find Similar functions
- Make calls to Khoj search API async to not block user interactions
- Support Conversation Sessions
- Create transient menu to open, create, delete conversation sessions from the Khoj Emacs client
- C-x o to switch to search org content conflicts with switch buffer shortkey
This is more apparent in the async search scenario as it prevents
perform other actions while async search is in progress
- Also switching content type wouldn't scale to all the content types
Khoj will support without causing more conflicting keybinding
Khoj side pane occupies a vertically split bottom right side pane.
If the bottom right window is not a vertical split, create a new
vertical split pane for khoj, otherwise reuse the existing window
- Fix getting file filters for not found conversations
- Allow iamge rendering in automation emails
- Fix nearest 15th minute calculation in automations creation
* added support for uploading multiple files at a time.
* optimized multiple file upload to use a batch upload
* allowing files to upload even if there is one unsupported file
See the currently active window in context while doing chat, search
or find similar operations in a side pane.
This is similar to how we've moved Khoj on Obsidian into the side pane
as well
# Major
- Disambiguate Text output mode to disambiguate from Default data source lookup
- Fix showing headings in intermediate step in generating chat response
- Remove "Path" prefix from org ancestor heading in compiled entry
# Minor
- Fix OpenAI chat actor, director unit tests
* Add language-specific syntax highlighting via highlight.js
- Add highlight.js to our assets CDN for fast load and compliance with the CSP
- See other stylesheets options here: https://cdnjs.com/libraries/highlight.js
* Bonus: set min-height to prevent increasing length of the sessions pane
* Fix references rendering and add highlight.js in public conversation
* Fix multilingual font rendering; fallback to an Arabic language font which contains more Asian characters. Close#756
* Tune font-sizes and styling to accomodate new fonts with old sizing
- Move connection-status styling out from inline html into css block
- Remove start typing chat-input height jitter
- align new-conversation button, text
- use relative font sizes instead of absolute font sizes in most places
---------
Co-authored-by: Debanjum Singh Solanky <debanjum@gmail.com>
* UI update for file filtered conversations
* Interactive file menu #UI to add/remove files on each conversation as references.
* Backend changes implemented to load selected file filters from a conversation into the querying process.
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
Previously if default output was selected by Khoj, we'd end up doing
an documents search as well, even when Khoj selected internet or
general data source to lookup.
This update disambiguates the default information mode from the text
output mode. To avoid doing documents search when not deemed necessary
by Khoj
Prevent XSS attacks by enforcing Content-Security-Policy (CSP) in apps.
Do not allow loading images, other assets from untrusted domains.
- Only allow loading assets from trusted domains
like 'self', khoj.dev, ipapi for geolocation, google (fonts, img)
- images from khoj domain, google (for profile pic)
- assets from khoj domain
- Do not allow iframe src
- Allow unsafe-inline script and styles for now as markdown-it escapes html
in user, khoj chat
- Add hostURL to CSP of the Desktop, Obsidian apps
Given web client is served by khoj server, it doesn't need to
explicitly allow for khoj.dev domain. So if user self-hosting, it'll
automatically allow the domain in the CSP (via 'self')
Whereas the Obsidian, Desktop clients allow configure the server URL.
Note *switching server URL breaks CSP until app is reloaded*
* The command menu (triggered by "/") now has a clickable list of possible commands, that automatically fill into the chat when pressed.
* The `/help` command now searches `khoj.dev` pages to provide useful assistance to the user.
---------
Co-authored-by: raghavt3 <raghavt3@illinois.edu>
Co-authored-by: sabaimran <65192171+sabaimran@users.noreply.github.com>
### Details
- **Chat with Khoj from right pane on Obsidian**
- Modal was too ephemeral, couldn't have it open for reference, quick jump to Khoj chat
- **Stream intermediate steps taken by Khoj** for generating response to the chat pane
Gives more transparency into Khoj 'thinking' process, e.g internet, notes searches performed, documents read etc.
The feedback allows us to tune our messages to elicit better responses by Khoj
- Add ability to **copy message to clipboard, paste chat messages directly into current file**
- Jump to **Search**, **Find Similar** functions from navigation bar on the Khoj Obsidian side pane
- Improve spacing, use consistent colors in chat message references and buttons
Resolves#789, #754
* Updating the API / UI to support sharing of automations
* Allow people to see the automations even when not logged in, and add an overlay effect
* Handle unauthenticated users taking actions
* Support showing pre-filled automation details on the config automations page
* Redirect user to login if they try to add an automation while unauthenticated
- Dedupe the code to add action buttons to chat messages
- Update the renderIncrementalMessage function to also add the action
buttons to newly generated chat messages by Khoj
* Disable automation recurrence at minute level frequency
* Set a max lifetime for django's connections to the db
* Disable any automation that has a non-numeric first digit (i.e., recuring on the minute level)
* Re-enable automations
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
Previously clicking inline links would open the URL directly in the
Desktop app. This was strange and it didn't provide any way to go back
to Khoj desktop app UI from the opened link
- Don't propagate max_tokens to the openai chat completion method. the max for the newer models is fixed at 4096 max output. The token limit is just used for input
* Add support for chatting with Anthropic's suite of models
- Had to use a custom class because there was enough nuance with how the anthropic SDK works that it would be better to simply separate out the logic. The extract questions flow needed modification of the system prompt in order to work as intended with the haiku model
- Pass file path of reference along with the compiled reference in
list of references returned by chat API converts
- Update the structure of references from list of strings to list of
dictionary (containing 'compiled' and 'file' keys)
- Pull out the compiled reference from the new references data struct
wherever it was is being used
Simplify, reuse, standardize code to render messages with references
in the obsidian, web and desktop clients. Specifically:
- Reuse function to create reference section, dedupe code
- Create reusable function to generate image markdown
- Simplify logic to render message with references
- Setup websocket using Khoj web app as reference.
- Moved the geolocating code to chat view out from the general pane
view
- Use loading spinner from web instead of the thinking emoji
It'll replace any highlighted text with the chat message or if not
text is highlighted, it'll insert the chat message at the last cursor
position in the active file
- Jump to chat, show similar actions from nav menu of Khoj side pane
- Add chat, search icons from web, desktop app
- Use lucide icon for find similar (for now)
- Match proportions of find similar icon to khoj other icons via css, js
- Use KhojPaneView abstract class to allow reuse of common functionality like
- Creating the nav bar header in side pane views
- Loading geo-location data for chat context
This should make creating new views easier
* Update suggested automations
* add a schedule picker when creating an automation
* Create a new conversation in flow of the automation scheduling in order to send a preview and deliver more consistent results
* Start adding in scaffolding to manually trigger a test job for an automation
* Add support for manually triggering automations for testing
* Schedule automation asynchronously
* Update styling of the preview button
* Improve admin lookup experience and prevent jobs from being scheduled to run every minute of everyday
* Ignore mypy issues on job info short description
### Description and Rationale for Changes
This feature includes thumbs up and thumbs down buttons on Khoj's chat responses that provide automated feedback. When a thumbs up/down button is clicked, the code sends an email to team@khoj.dev with the following:
* user query
* khoj's response
* whether the sentiment of the user was good or bad.
This is critical in improving Khoj's nondeterministic LLM model for a better user experience.
### List of Changes
* new endpoint in `api_chat.py` (/feedback) that can be used to trigger mail sending).
* thumbs up and thumbs down buttons implemented in `chat.html`
* new function in `routers/email.py` to handle feedback email sending via resend
* `feedback.html` template for a formatted email with the feedback.
---------
Co-authored-by: mythicalcow <mythicalcow@linux.myguest.virtualbox.org>
Co-authored-by: sabaimran <narmiabas@gmail.com>
* Improve the automations UX
- Add suggested jobs to elimiinate some of the cold start problem
- Make each of the tasks cards that are clickable/editable
* Hide suggested automations that have already been added
* Add a footer and reapply styling when a save action is taken on a card
- Allows having it open on the side as you traverse your Obsidian notes
- Allow faster time to response, having responses visible for context
- Enables ambient interactions
* Make conversations optionally shareable
- Shared conversations are viewable by anyone, without a login wall
- Can share a conversation from the three dot menu
- Add a new model for Public Conversation
- The rationale for a separate model is that public and private conversations have different assumptions. Separating them reduces some of the code specificity on our server-side code and allows us for easier interpretation and stricter security. Separating the data model makes it harder to accidentally view something that was meant to be private
- Add a new, read-only view for public conversations
- Add parsing logic for LaTeX-format math equations in the web chat
- Add placeholder delimiters when converting the markdown to HTML in order to avoid removing the escaped characters
- Add the `<!DOCTYPE html>` specification to the page
## Support Scheduling Automations (#695)
1. Detect when user intends to schedule a task, aka reminder
- Support new `reminder` output mode to the response type chat actor
- Show examples of selecting the reminder output mode to the response type chat actor
2. Extract schedule time (as cron timestring) and inferred query to run from user message
3. Use APScheduler to call chat with inferred query at scheduled time
## Make Automations Persistent (#714)
- Make scheduled jobs persistent and work in multiple worker setups
- Add new operation Scheduled Job to Operation enum of ProcessLock
## Add UX to Configure Scheduled Tasks (#715)
- Add section in settings page to view, delete your scheduled tasks
- Add API endpoints to get and delete user scheduled tasks
## Make Automations more Robust. Improve UX (#718)
- Decouple Task Run from User Notification
- Make Scheduling more Robust
- Use JSON mode to get parse-able output from chat model
- Make timezone calculation programmatic on server instead of asking chat model
- Use django-apscheduler to handle apscheduler and django interfacing
- Improve automation UX. Move it out into separate top level page
- Allow creating, modifying automations from the automations page
- Infer cron from natural language client side to avoid roundtrip
- Pass user and calling_url to the scheduled chat too when modifying
params of automation
- Update to use user timezone even when update job via API
- Move timezone string to timezone object calculation into the
schedule automation method
- Previously it was a section in the settings page. Move it to
independent, top-level page to improve visibility of feature
- Calculate crontime from natural language on web client before
sending it to to server for saving new/updated schedule to disk.
- Avoids round-trip of call to chat model
- Convert POST /api/automation API endpoint into a direct request for
automation with query_to_run, subject and schedule provided via the
automation page. This allows more granular control to create automation
- Make the POST automations endpoint more robust; runs validation
checks, normalizes parameters
- Make the config page content use the same top level 3-column layout
as the khoj-header-wrapper
This ensures the content is aligned with heading pane width
- Let cards and other settings sections scale to the width of their
grid element. This utilizes more of the screen space and does it
consistently across the different settings pages
- Create new POST API endpoint to create automations
- Use it in the settings page on the web interface to create
new automations
This simplified managing automations from the setting page by allowing
both delete and create from the same page
- Render crontime string in natural language in message & settings UI
- Show more fields in tasks web config UI
- Add link to the tasks settings page in task scheduled chat response
- Improve task variables names
Rename executing_query to query_to_run. scheduling_query to
scheduling_request
- Make timezone aware scheduling programmatic, instead of asking the
chat model to do the conversion. This removes the need for
scratchpad and may let smaller models handle the task as well
- Make chat model infer subject for email. This should make the
notification email more readable
- Improve email by using subject in email subject, task heading. Move
query to email final paragraph, which is where task metadata should
go
- Using inferred_query directly was brittle (like previous job id)
- And process lock id had a limited size, so wouldn't work for larger
inferred query strings
- Pass timezone string from ipapi to khoj via clients
- Pass this data from web, desktop and obsidian clients to server
- Use user tz to render next run time of scheduled task in user tz
This takes the load of the task scheduling chat actor / prompt from
having to artifically differentiate query to create scheduled task
from a scheduled task run.
- The task scheduling actor was having trouble calculating the
timezone. Giving the actor a scratchpad to improve correctness by
thinking step by step
- Add more examples to reduce chances of the inferred query looping to
create another reminder instead of running the query and sharing
results with user
- Improve task scheduling chat actor test with more tests and
by ensuring unexpected words not present in response
There's a difference between running a scheduled task and notifying
the user about the results of running the scheduled task.
Decide to notify the user only when the results of running the
scheduled task satisfy the user's requirements.
Use sync version of send_message_to_model_wrapper for scheduled tasks
- Store scheduled job state in Postgres so job schedules persist
across app restarts
- Use Process Locks to only allow single worker to process a given job
type. This prevents duplicating job runs across all workers
- Detect when user intends to schedule a task, aka reminder
Add new output mode: reminder. Add example of selecting the reminder
output mode
- Extract schedule time (as cron timestring) and inferred query to run
from user message
- Use APScheduler to call chat with inferred query at scheduled time
- Handle reminder scheduling from both websocket and http chat requests
- Support constructing scheduled task using chat history as context
Pass chat history to scheduled query generator for improved context
for scheduled task generation
Previously the make delete API response failed, after deleting token.
Required a page refresh to see that the API token was actually gone.
This was happening because the response type of the delete token API
endpoint isn't a string, so it failed FastAPI response validation
checks.
- Allow self-hosted users to customize their open ai base url. This allows you to easily use a proxy service and extend support for other models.
- This also includes a migration that associates any existing openai chat model configuration with an openai processor configuration
- Make changing model a paid/subscriber feature
- Removes usage of langchain's OpenAI wrapper for better control over parsing input/output
- Allow passing completion args through completion_with_backoff
- Pass model_kwargs in a separate arg to simplify this
- Pass model in `model_name' kwarg from the send_message_to_model func
`model_name' kwarg is used by langchain, not `model' kwarg
- Make valid file extension checking case insensitive on Desktop app
- Skip indexing non-existent folders on Desktop app
- Pass auth headers to fix lazy load of chat messages on Desktop app
- Set chat-message height to height of content in web, desktop
Previous cross-encoder model was a few years old, newer models should
have improved in quality. Model size increases by 50% compared to
previous for better performance, at least on benchmarks
Most newer, better embeddings models add a query, docs prefix when
encoding. Previously Khoj admins couldn't configure these, so it
wasn't possible to use these newer models.
This change allows configuring the kwargs passed to the query, docs
encoders by updating the search config in the database.
Improve tool, online search, webpage links, docs search chat actor
prompts. Ensure works with hermes-2-pro and llama-3.
Be more specific about generating JSON and not saying anything else.
- Improve extract question prompts to explicitly request JSON list
- Use llama-3 chat format if HF repo_id mentions llama-3. The
llama-cpp-python logic for detecting when to use llama-3 chat format
isn't robust enough currently
* Changed the styling of the link that takes a user to the settings page into a button
* added an indicator that shows if a user is connected to the server or not
* made a class name more descriptive and also made the text in first run message more intuitive
* changed the command to install dependencies in the README.md
* changed the class name of the first run message text to be more descriptive
* added icons in the desktop UI that shows if a file is synced successfully or not
* made the link class name in the homepage more descriptive
* fixed the hover issue on status box in the chat header pane
* fixed hovering issue on status box on macOS
- User configured max tokens limits weren't being passed to
`send_message_to_model_wrapper'
- One of the load offline model code paths wasn't reachable. Remove it
to simplify code
- When max prompt size isn't set infer max tokens based on free VRAM
on machine
- Use min of app configured max tokens, vram based max tokens and
model context window
- User configured max tokens limits weren't being passed to
`send_message_to_model_wrapper'
- One of the load offline model code paths wasn't reachable. Remove it
to simplify code
- When max prompt size isn't set infer max tokens based on free VRAM
on machine
- Use min of app configured max tokens, vram based max tokens and
model context window
To access the Khoj admin panel from a non HTTPS custom domain the
`KHOJ_NO_SSL' and `KHOJ_DOMAIN' env vars need to be explictly set.
See the updated setup docs for details.
Resolves#662
### Store Generated Images as WebP
- 78bac4ae Add migration script to convert PNG to WebP references in database
- c6e84436 Update clients to support rendering webp images inline
- d21f22ff Store Khoj generated images as webp instead of png for faster loading
### Lazy Fetch Chat Messages to Improve Time, Data to First Render
This is especially helpful for long conversations with lots of images
- 128829c4 Render latest msgs on chat session load. Fetch, render rest as they near viewport
- 9e558577 Support getting latest N chat messages via chat history API
### Intelligently set Context Window of Offline Chat to Improve Performance
- 4977b551 Use offline chat prompt config to set context window of loaded chat model
### Fixes
- 148923c1 Fix to raise error on hitting rate limit during Github indexing
- b8bc6bee Always remove loading animation on Desktop app if can't login to server
- 38250705 Fix `get_user_photo` to only return photo, not user name from DB
### Miscellaneous Improvements
- 689202e0 Update recommended CMAKE flag to enable using CUDA on linux in Docs
- b820daf3 Makes logs less noisy
- Reduces time to first render when loading long chat sessions
- Limits size of first page load, when loading long chat sessions
These performance improvements are maximally felt for large chat
sessions with lots of images generated by Khoj
Updated web and desktop app to support these changes for now
Previously you couldn't configure the n_ctx of the loaded offline chat
model. This made it hard to use good offline chat model (which these
days also have larger context) on machines with lower VRAM
- Show telemetry enabled/disabled state on init, not every 2 minutes
- Convert no docs synced logs to debug level instead of warning
Having synced docs isn't as important to use Khoj now, unlike before
- Magika on Desktop app was too bloated (100Mb to 250Mb) and broke
install for some reason. Not sure why it was causing the app install
to fail but do not have time to currently investigate
- Just use file extensions whitelist it's good enough for now. Let
server handle the deeper identification of file type
### Index more text file types
- Index all text, code files in Github repos. Not just md, org files
- Send more text file types from Desktop app and improve indexing them
- Identify file type by content & allow server to index all text files
### Deprecate Github Indexing Features
- Stop indexing commits, issues and issue comments in a Github repo
- Skip indexing Github repo on hitting Github API rate limit
### Fixes and Improvements
- **Fix indexing files in sub-folders from Desktop app**
- Standardize structure of text to entries to match other entry processors
- Show internet search, webpage read, image query, image generation steps
- Standardize, improve rendering of the intermediate steps on the web app
Benefits:
1. Improved transparency, allow users to see what Khoj is doing behind
the scenes and modify their query patterns to improve response quality
2. Reduced websocket connection keep alive timeouts for long running steps
- `file-type' doesn't handle mis-labelled files or files without
extensions well
- Only show supported file types in file selector dialog on Desktop app
Use Magika to get list of text file extensions. Combine with other
supported extensions to get complete list of supported file extensions.
Use it to limit selectable files in the File Open dialog.
Note: Folder selector will index text files with no extensions as well
* Don't trigger any re-indexing on server initailization
* Integrate Resend to send welcome emails when a new user signs up
- Only send if this is the first time they've signed in
- Configure welcome email with basic styling, as more complex designs don't work and style tag did not work
### Enable copying chat messages. Improve copy button behavior and styling
- Add button to copy chat messages on Desktop, Web apps
- Improve copy button's icon, hover color & click animation in Desktop, Web apps
### Improve Navigation, Chat Session Panes on Desktop, Web apps
- Dynamically generate navigation menu based on user info from server
- Create API endpoint to get authenticated user information
- Collapse navigation tabs into icons on mobile. Add spacing to them
- Add Chat navigation tab back to top pane on Web app
- Use proper icons for Search, Chat and Agents tab on navigation pane
### Miscellaneous Improvements
- Make current chat expand to full width when session panel collapsed on Desktop App
- Add chat session loading spinner to Desktop App (same as Web app)
### Fixes
- Show title bar in Khoj desktop app on Windows to simplify close, minimize etc.
- Only render first run setup message once if error or server not running
- Fix showing Search navigation tab from Agent pages on web client
The username and location in system prompt should disambiguate user
context from user's actual message for the chat model.
It doesn't need to be told to not mention the context or acknowledge
the context instructions in it's response, as it understands that this
information is just context and not part of the user's actual message.
- Move new conversation button to right of "Conversation" title
- Reduce size of chat message loading ellipsis animation
- Add loading animation for chat session
The `has_documents' flag wasn't being passed. So the search tab
always showing up as empty instead of being dynamically enabled if
documents had been indexed.
- `fs.readdir' func in node version 18.18.2 has buggy `recursive' option
See nodejs/node#48640, effect-ts/effect#1801 for details
- We were recursing down a folder in two ways on the Desktop app.
Remove `recursive: True' option to the `fs.readdirSync' method call
to recurse down via app code only
Add process_single_plaintext_file func etc with similar signatures as
org_to_entries and markdown_to_entries processors
The standardization makes modifications, abstractions easier to create
Sleep until rate limit passed is too expensive, as it keeps a
app worker occupied.
Ideally we should schedule job to contine after rate limit wait time
has passed. But this can only be added once we support jobs scheduling.
Normal indexing quickly Github hits rate limits. Purpose of exposing
Github indexer is for indexing content like notes, code and other
knowledge base in a repo.
The current indexer doesn't scale to index metadata given Github's
rate limits, so remove it instead of giving a degraded experience of
partially indexed repos
- Allow syncing more file types from desktop app to index on server
- Use `file-type' package to identify valid text file types on Desktop app
- Split plaintext entries into smaller logical units than a whole file
Since the text splitting upgrades in #645, compiled chunks have more
logical splits like paragraph, sentence.
Show those (potentially) smaller snippets to the user as references
- Tangential Fix:
Initialize unbound currentTime variable for error log timestamp
- Use Magika's AI for a tiny, portable and better file type
identification system
- Existing file type identification tools like `file' and `magic'
require system level packages, that may not be installed by default
on all operating systems (e.g `file' command on Windows)
## Major
- Parse markdown, org parent entries as single entry if fit within max tokens
- Parse a file as single entry if it fits with max token limits
- Add parent heading ancestry to extracted markdown entries for context
- Chunk text in preference order of para, sentence, word, character
## Minor
- Create wrapper function to get entries from org, md, pdf & text files
- Remove unused Entry to Jsonl converter from text to entry class, tests
- Dedupe code by using single func to process an org file into entries
Resolves#620
### Why
- Python 3.12 is the default Python on Ubuntu 24.04 LTS, Windows and Mac via Homebrew
- Python 3.12 has a bunch of improvements that can be explored with Khoj (e.g per core GIL for performance)
## Changes
- The latest PyTorch now supports Python 3.12
- RapidOCR for indexing image PDFs doesn't currently support python 3.12.
But it's an optional dependency, so only install it if python < 3.12
### Testing
- Verified Khoj installs fine on Windows and Mac with Python 3.12
- Verified Khoj chat works fine on Mac, Windows with Python 3.12
Resolves#522
- RapidOCR for indexing image PDFs doesn't currently support python 3.12.
It's an optional dependency anyway, so only install it if python < 3.12
- Run unit tests with python version 3.12 as well
Resolves#522
* Add support for using OAuth2.0 in the Notion integration
* Add notion to the admin page
* Remove unnecessary content_index and image search/setup references
* Trigger background job to start indexing Notion after user configures it
* Add a log line when a new Notion integration is setup
* Fix references to the configure_content methods
`re.MULTILINE' should be passed to the `flags' argument, not the
`max_splits' argument of the `re.split' func
This was messing up the indexing by only allowing a maximum of
re.MULTILINE splits. Fixing this improves the search quality to
previous state
More content indexed per entry would result in an overall scores
lowering effect. Increase default search distance threshold to counter that
- Details
- Fix expected results post indexing updates
- Fix search with max distance post indexing updates
- Minor
- Remove openai chat actor test for after: operator as it's not expected anymore
- Major
- Do not split org file, entry if it fits within the max token limits
- Recurse down org file entries, one heading level at a time until
reach leaf node or the current parent tree fits context window
- Update `process_single_org_file' func logic to do this recursion
- Convert extracted org nodes with children into entries
- Previously org node to entry code just had to handle leaf entries
- Now it recieve list of org node trees
- Only add ancestor path to root org-node of each tree
- Indent each entry trees headings by +1 level from base level (=2)
- Minor
- Stop timing org-node parsing vs org-node to entry conversion
Just time the wrapping function for org-mode entry extraction
This standardizes what is being timed across at md, org etc.
- Move try/catch to `extract_org_nodes' from `parse_single_org_file'
func to standardize this also across md, org
These changes improve context available to the search model.
Specifically this should improve entry context from short knowledge trees,
that is knowledge bases with sparse, short heading/entry trees
Previously we'd always split markdown files by headings, even if a
parent entry was small enough to fit entirely within the max token
limits of the search model. This used to reduce the context available
to the search model to select appropriate entries for a query,
especially from short entry trees
Revert back to using regex to parse through markdown file instead of
using MarkdownHeaderTextSplitter. It was easier to implement the
logical split using regexes rather than bend MarkdowHeaderTextSplitter
to implement it.
- DFS traverse the markdown knowledge tree, prefix ancestry to each entry
These changes improve entry context available to the search model
Specifically this should improve entry context from short knowledge trees,
that is knowledge bases with small files
Previously we split all markdown files by their headings,
even if the file was small enough to fit entirely within the max token
limits of the search model. This used to reduce the context available
to select the appropriate entries for a given query for the search model,
especially from short knowledge trees
- Previous simplistic chunking strategy of splitting text by space
didn't capture notes with newlines, no spaces. For e.g in #620
- New strategy will try chunk the text at more natural points like
paragraph, sentence, word first. If none of those work it'll split
at character to fit within max token limit
- Drop long words while preserving original delimiters
Resolves#620
This was earlier used when the index was plaintext jsonl file. Now
that documents are indexed in a DB this func is not required.
Simplify org,md,pdf,plaintext to entries tests by removing the entry
to jsonl conversion step
- Convert extract_org_entries function to actually extract org entries
Previously it was extracting intermediary org-node objects instead
Now it extracts the org-node objects from files and converts them
into entries
- Create separate, new function to extract_org_nodes from files
- Similarly create wrapper funcs for md, pdf, plaintext to entries
- Update org, md, pdf, plaintext to entries tests to use the new
simplified wrapper function to extract org entries
- Move green server connected dot to the bottom. Show status when
disconnected from server
- Move "New conversation" button to right of the "Conversation" title
- Center alignment of the new conversation and connection status buttons
- Overview
- Extract more structured date variants (e.g with dot(.) & slash(/) separators, 2-digit year)
- Extract some natural, partial dates as well from entries
- Capability
Add ability to extract the following additional date forms:
- Natural Dates: 21st April 2000, February 29 2024
- Partial Natural Dates: March 24, Mar 2024
- Structured Dates: 20/12/24, 20.12.2024, 2024/12/20
Note: Previously only YYYY-MM-DD ISO-8601 structured date form was extracted for date filters
- Performance
Using regexes is MUCH faster than using the `dateparser' python library
It's a little crude but gives acceptable performance for large datasets
## Benefits
- Support all GGUF format chat models
- Support more GPUs like AMD, Nvidia, Mac, Vulcan (previously just Vulcan, Mac)
- Support more capabilities like larger context window, schema enforcement, speculative decoding etc.
## Changes
### Major
- Use llama.cpp for offline chat models
- Support larger context window
- Automatically apply appropriate chat template. So offline chat models not using llama2 format are now supported
- Use better default offline chat model, NousResearch/Hermes-2-Pro-Mistral-7B
- Enable extract queries actor to improve notes search with offline chat
- Update documentation to use llama.cpp for offline chat in Khoj
### Minor
- Migrate to use NouseResearch's Hermes-2-Pro 7B as default offline chat model in khoj.yml
- Rename GPT4AllChatProcessor to OfflineChatProcessor Config, Model
- Only add location to image prompt generator when location known
- Much faster than using dateparser
- It took 2x-4x for improved regex to extracts 1-15% more dates
- Whereas It took 33x to 100x for dateparser to extract 65% - 400% more dates
- Improve date extractor tests to test deduping dates, natural,
structured date extraction from content
- Extract some natural, partial dates and more structured dates
Using regex is much faster than using dateparser. It's a little
crude but should pay off in performance.
Supports dates of form:
- (Day-of-Month) Month|AbbreviatedMonth Year|2DigitYear
- Month|AbbreviatedMonth (Day-of-Month) Year|2DigitYear
Previously we just extracted dates in YYYY-MM-DD format from content
for date filterings during search.
Use dateparser to extract dates across locales and natural language
This should improve notes returned as context when chat searches
knowledge base with date filters
Fallback to regex for date parsing from content if dateparser fails
- Limit natural date extractor capabilities to improve performance
- Assume language is english
Language detection otherwise takes a REALLY long time
- Do not extract unix timestamps, timezone
- This isn't required, as just using date and approximating dates as UTC
- When setting up the default agent, configure every conversation that doesn't have an agent to use the Khoj agent
- Fix reverse migration for the locale removal migration
Previously we were skipping the extract questions step for offline
chat as default offline chat model wasn't good enough to output proper
json given the time it took to extract questions.
The new default offline chat models gives json much more regularly and
with date filters, so the extract questions step becomes useful given
the impact on latency
- How to pip install khoj to run offline chat on GPU
After migration to llama-cpp-python more GPU types are supported but
require build step so mention how
- New default offline chat model
- Where to get supported chat models from on HuggingFace
- Benefits of moving to llama-cpp-python from gpt4all:
- Support for all GGUF format chat models
- Support for AMD, Nvidia, Mac, Vulcan GPU machines (instead of just Vulcan, Mac)
- Supports models with more capabilities like tools, schema
enforcement, speculative ddecoding, image gen etc.
- Upgrade default chat model, prompt size, tokenizer for new supported
chat models
- Load offline chat model when present on disk without requiring internet
- Load model onto GPU if not disabled and device has GPU
- Load model onto CPU if loading model onto GPU fails
- Create helper function to check and load model from disk, when model
glob is present on disk.
`Llama.from_pretrained' needs internet to get repo info from
HuggingFace. This isn't required, if the model is already downloaded
Didn't find any existing HF or llama.cpp method that looked for model
glob on disk without internet
* Initial pass at backend changes to support agents
- Add a db model for Agents, attaching them to conversations
- When an agent is added to a conversation, override the system prompt to tweak the instructions
- Agents can be configured with prompt modification, model specification, a profile picture, and other things
- Admin-configured models will not be editable by individual users
- Add unit tests to verify agent behavior. Unit tests demonstrate imperfect adherence to prompt specifications
* Customize default behaviors for conversations without agents or with default agents
* Add a new web client route for viewing all agents
* Use agent_id for getting correct agent
* Add web UI views for agents
- Add a page to view all agents
- Add slugs to manage agents
- Add a view to view single agent
- Display active agent when in chat window
- Fix post-login redirect issue
* Fix agent view
* Spruce up the 404 page and improve the overall layout for agents pages
* Create chat actor for directly reading webpages based on user message
- Add prompt for the read webpages chat actor to extract, infer
webpage links
- Make chat actor infer or extract webpage to read directly from user
message
- Rename previous read_webpage function to more narrow
read_webpage_at_url function
* Rename agents_page -> agent_page
* Fix unit test for adding the filename to the compiled markdown entry
* Fix layout of agent, agents pages
* Merge migrations
* Let the name, slug of the default agent be Khoj, khoj
* Fix chat-related unit tests
* Add webpage chat command for read web pages requested by user
Update auto chat command inference prompt to show example of when to
use webpage chat command (i.e when url is directly provided in link)
* Support webpage command in chat API
- Fallback to use webpage when SERPER not setup and online command was
attempted
- Do not stop responding if can't retrieve online results. Try to
respond without the online context
* Test select webpage as data source and extract web urls chat actors
* Tweak prompts to extract information from webpages, online results
- Show more of the truncated messages for debugging context
- Update Khoj personality prompt to encourage it to remember it's capabilities
* Rename extract_content online results field to webpages
* Parallelize simple webpage read and extractor
Similar to what is being done with search_online with olostep
* Pass multiple webpages with their urls in online results context
Previously even if MAX_WEBPAGES_TO_READ was > 1, only 1 extracted
content would ever be passed.
URL of the extracted webpage content wasn't passed to clients in
online results context. This limited them from being rendered
* Render webpage read in chat response references on Web, Desktop apps
* Time chat actor responses & chat api request start for perf analysis
* Increase the keep alive timeout in the main application for testing
* Do not pipe access/error logs to separate files. Flow to stdout/stderr
* [Temp] Reduce to 1 gunicorn worker
* Change prod docker image to use jammy, rather than nvidia base image
* Use Khoj icon when Khoj web is installed on iOS as a PWA
* Make slug required for agents
* Simplify calling logic and prevent agent access for unauthenticated users
* Standardize to use personality over tuning in agent nomenclature
* Make filtering logic more stringent for accessible agents and remove unused method:
* Format chat message query
---------
Co-authored-by: Debanjum Singh Solanky <debanjum@gmail.com>
### Overview
Khoj can now read website directly without needing to go through the search step first
### Details
- Parallelize simple webpage read and extractor
- Rename extract_content online results field to web pages
- Tweak prompts to extract information from webpages, online results
- Test select webpage as data source and extract web urls chat actors
- Render webpage read in chat response references on Web, Desktop apps
- Pass multiple webpages with their urls in online results context
- Support webpage command in chat API
- Add webpage chat command for read web pages requested by user
- Create chat actor for directly reading webpages based on user message
Previously even if MAX_WEBPAGES_TO_READ was > 1, only 1 extracted
content would ever be passed.
URL of the extracted webpage content wasn't passed to clients in
online results context. This limited them from being rendered
- Fallback to use webpage when SERPER not setup and online command was
attempted
- Do not stop responding if can't retrieve online results. Try to
respond without the online context
* Initial pass at backend changes to support agents
- Add a db model for Agents, attaching them to conversations
- When an agent is added to a conversation, override the system prompt to tweak the instructions
- Agents can be configured with prompt modification, model specification, a profile picture, and other things
- Admin-configured models will not be editable by individual users
- Add unit tests to verify agent behavior. Unit tests demonstrate imperfect adherence to prompt specifications
* Customize default behaviors for conversations without agents or with default agents
* Use agent_id for getting correct agent
* Merge migrations
* Simplify some variable definitions, add additional security checks for agents
* Rename agent.tuning -> agent.personality
- Use the conversation id of the retrieved conversation rather than the
potentially unset conversation id passed via API
- await creating new chat when no chat id provided and no existing
conversations exist
- Move some common methods into separate functions to make the UI components more efficient
- The normal HTTP-based chat connection will still work and serves as a fallback if the websocket is unavailable
- Convert to a model of calling the search API directly with a function call (rather than using the API method)
- Gracefully handle websocket connection disconnects
- Ensure that the rest of the response is still saved, as it is currently, if the user disconects from the client
- Setup unchangeable context at the beginning of the session when the connection is established (like location, username, etc)
The recently added after: operator to online search actor was too
restrictive, gave worse results than when just use natural language
dates in search query
### Improve
- Improve delete, rename chat session UX in Desktop, Web app
- Get conversation by title when requested via chat API
### Fix
- Allow unset locale for Google authenticating user
- Handle truncation when single long non-system chat message
- Fix setting chat session title from Desktop app
- Only create new chat on get if a specific chat id, slug isn't requested
Previously was assuming the system prompt is being always passed as
the first message. So expected there to be at least 2 messages in logs.
This broke chat actors querying with single long non system message.
A more robust way to extract system prompt is via the message role
instead
- Ask for Confirmation before deleting chat session in Desktop, Web app
- Save chat session rename on hitting enter in title edit input box
- No need to flash previous conversation cleared status message
- Move chat session delete button after rename button in Desktop app
- Add prompt for the read webpages chat actor to extract, infer
webpage links
- Make chat actor infer or extract webpage to read directly from user
message
- Rename previous read_webpage function to more narrow
read_webpage_at_url function
### Major
- Enforce json mode response from OpenAI chat actors prev using string lists
- Use `gpt-4-turbo-preview' as default chat model, extract questions actor
- Make Khoj read khoj website to respond with accurate, up-to-date information about itself
- Dedupe query in notes prompt. Improve OAI chat actor, director tests
### Minor
- Test data source, output mode selector, web search query chat actors
- Improve notes search actor to always create a non-empty list of queries
- Construct available data sources, output modes as a bullet list in prompts
- Use consistent agent name across static and dynamic examples in prompts
- Add actor's name to extract questions prompt to improve context for guidance
Previously only the notes references would get rendered post response
streaming when when both online and notes references were used to
respond to the user's message
- Allow passing response format type to OpenAI API via chat actors
- Convert in-context examples to use json objects instead of str lists
- Update actors outputting str list to request output to be json_object
- OpenAI's json mode enforces the model to output valid json object
- Remove stale tests
- Improve tests to pass across gpt-3.5 and gpt-4-turbo
- The haiku creation director was failing because of duplicate query in
instantiated prompt
- Remove the option for Notes search query generation actor to return
no queries. Whether search should be performed is decided before,
this step doesn't need to decide that
- But do not throw warning if the response is a list with no elements
- Add examples where user queries requesting information about Khoj
results in the "online" data source being selected
- Add an example for "general" to select chat command prompt
Previously the examples constructed from chat history used "Khoj" as
the agent's name but all 3 prompts using the func used static examples
with "AI:" as the pertinent agent's name
- Add example to read khoj.dev website for up-to-date info to setup,
use khoj, discover khoj features etc.
- Online search should use site: and after: google search operators
- Show example of adding the after: date filter to google search
- Give local event lookup example using user's current location in
query
- Remove unused select search content type prompt
- Add a page to view all agents
- Add slugs to manage agents
- Add a view to view single agent
- Display active agent when in chat window
- Fix post-login redirect issue
### Major
- Read web pages in parallel to improve chat response time
- Read web pages directly when Olostep proxy not setup
- Include search results & web page content in online context for chat response
### Minor
- Simplify, modularize and add type hints to online search functions
Previously if a web page was read for a sub-query, only the extracted
web page content was provided as context for the given sub-query. But
the google results themselves have relevant snippets. So include them
- Simplify content arg to `extract_relevant_info' function. Validate,
clean the content arg inside the `extract_relevant_info' function
- Extract `search_with_google' function outside the parent function
- Call the parent function a more appropriate `search_online' instead
of `search_with_google'
- Simplify the `search_with_google' function using list comprehension.
Drop empty search result fields from chat model context for response
to reduce cost and response latency
- No need to show stacktrace when unable to read webpage, basic error
is enough
- Add type hints to online search functions to catch issues with mypy
- Time reading webpage, extract info from webpage steps for perf
analysis
- Deduplicate webpages to read gathered across separate google
searches
- Use aiohttp to make API requests non-blocking, pair with asyncio to
parallelize all the online search webpage read and extract calls
- Add a db model for Agents, attaching them to conversations
- When an agent is added to a conversation, override the system prompt to tweak the instructions
- Agents can be configured with prompt modification, model specification, a profile picture, and other things
- Admin-configured models will not be editable by individual users
- Add unit tests to verify agent behavior. Unit tests demonstrate imperfect adherence to prompt specifications
- Trigger
SentenceTransformer Cross Encoder models now run fast on GPU enabled machines, including Mac ARM devices since UKPLab/sentence-transformers#2463
- Details
- Use cross-encoder to rerank search results by default on GPU machines and when using an inference server
- Only call search API when pause in typing search query on web, desktop apps
Wait for 300ms since stop typing before calling search API.
This smooths out UI jitter when rendering search results, especially
now that we're reranking for every search query on GPU enabled devices
Emacs already has 300ms debounce time. More convoluted to add
debounce time to Obsidian search modal, so not updating that yet
Latest sentence-transformer package uses GPU for cross-encoder. This
makes it fast enough to enable reranking on machines with GPU.
Enabling search reranking by default allows (at least) users with GPUs
to side-step learning the UI affordance to rerank results
(i.e hitting Cmd/Ctrl-Enter or ENTER).
### Issue
Previously deleting a chat session from the side panel on desktop, web app would sometimes result in also creating a new chat session
### Fix
`get_conversation_by_user' shouldn't return new conversation if
conversation with requested id not found.
It should only return new conversation if no specific conversation
is requested and no conversations found for user at all
### Miscellaneous Improvements
- Chat history load should be logged as call to that chat_history api,
not the "chat" api
- Show status updates of clearing conversation history in chat input
- Simplify web, desktop client code by removing unnecessary new variables
### Repro
- Delete a new chat, this calls loadChat via window.onload which
calls server /chat/history API endpoint with conversationId set to
that of just deleted conversation sporadically
The call to GET chat/history API with conversationId set occurs
when window.onload triggers before the conversationId is deleted
by the delete button after the DELETE /chat/history API call (via race)
- In such a scenario, get_conversation_by_user called by
chat/history API with conversationId of deleted conversation
returns a new conversation
- Fix
`get_conversation_by_user' shouldn't return new conversation if
conversation with requested id not found.
It should only return new conversation if no specific conversation
is requested and no conversations found for user at all
- Repro
- Delete a new chat, this calls loadChat via window.onload which
calls server /chat/history API endpoint with conversationId set to
that of just deleted conversation sporadically
The call to GET chat/history API with conversationId set occurs
when window.onload triggers before the conversationId is deleted
by the delete button after the DELETE /chat/history API call (via race)
- In such a scenario, get_conversation_by_user called by
chat/history API with conversationId of deleted conversation
returns a new conversation
- Miscellaneous
- Chat history load should be logged as call to that chat_history api,
not the "chat" api
- Show status updates of clearing conversation history in chat input
- Simplify web, desktop client code by removing unnecessary new variables
* Upload generated images to s3, if AWS credentials and bucket is available.
- In clients, render the images via the URL if it's returned with a text-to-image2 intent type
* Make the loading screen more intuitve, less jerky and update the programmatic copy button
* Update the loading icon when waiting for a chat response
* Add additional styling changes for showing UI changes when dragging file to the main screen
* Add a loading spinner when file upload is in progress, and don't index github/notion when indexing files
* Add an explicit icon for file uploading in the chat button menu
* Add appropriate dragover styling when picking a file from the file picker/browser
* Add a loading screen when retrieving chat history. Fix width of the chat window. Put attachment icon to the left of chat input
* Make major improvements to the image generation flow
- Include user context from online references and personal notes for generating images
- Dynamically select the modality that the LLM should respond with
- Retun the inferred context in the query response for the dekstop, web chat views to read
* Add unit tests for retrieving response modes via LLM
* Move output mode unit tests to the actor suite, rather than director
* Only show the references button if there is at least one available
* Rename aget_relevant_modes to aget_relevant_output_modes
* Use a shared method for generating reference sections, simplify some of the prompting logic
* Make out of space errors in the desktop client more obvious
- Open external links using the default link handler registered on OS
for the link type, e.g http:// -> firefox, mailto: thunderbird etc
- Confirm before opening non-http URL using an external app
- Improve render of inferred query in image chat messages in Web, Desktop apps
- Add inferred queries to image chat responses in Obsidian client
- Fix rendering images from Khoj response in Obsidian client
* Simplify and clarify prompt for selecting toolset dynamically
* Add error handling around call to OLOSTEP api
* Fix conversation admin page
* Skip adding none or empty entries in the chunking method
- Improve
- Only send files modified since their last sync for indexing on server from the Obsidian client
- Fix
- Invalidate static asset browser cache in Web client when Khoj version changes
Previously we'd send all files in vault and let the server
deduplicate.
This changes takes inspiration from the desktop app, and only pushes
files which were modified after their previous sync with the server.
This should reduce the processing load on the server
* Retrieve, create, and save conversations differently if they're coming from a client application
- Not all of our client apps will necessarily maintain state over the conversation IDs available to a user. For some (single-threaded conversations), it should just use a single conversation. Fix the code to do so
* Simplify conversation retrieval logic
* Keep 0 padding below chat response
* Add order_by sorting to retrieving the conversation without id
### Improvements to Chat UI on Web, Desktop apps
- Improve styling of chat session side panel
- Improve styling of chat message bubble in Desktop, Web app
- Add frosted, minimal chat UI to background of Login screen
- Improve PWA install experience of Khoj
### Fixes to Chat UI on Web, Desktop apps
- Fix creating new chat sessions from the Desktop app
- Only show 3 starter questions even when consecutive chat sessions created
### Other Improvements
- Update Khoj cloud trial period to a fortnight instead of a week
- Document using venv to handle dependency conflict on khoj pip install
Resolves#276
- Resolve PWA issues thrown by Chrome/Edge
- Add screenshot samples showcasing remember, browse and draw features
- This can provide a richer app store like experience when
installing Khoj PWA on Mobile or Desktop
- Add wide and narrow screenshots to show Mobile vs Desktop UX
- Add higher resolution favicon for PWA
- Use single web manifest instead of separate ones for Chat, Search
- Update manifest description with more details about Khoj features
Reset starter question suggestions before appending in web, desktop app
Otherwise previously it'd keep adding to existing starter question
suggestions on each new session creation if multiple consecutive new
chat sessions created.
This would result in more than the 3 expected starter questions being
displayed at a time
- Make collapse, expand toggle arrow point in the direction the action
will expand the side panel in
- Make the collapsed side panel reduce to a 1px sliver
- Improve rate limit error message wording
- Make the "too many requests" error message more robust. Should throw
that exception fix self.request >= self.subscribed_requests because
upgrading wouldn't fix this rate limiting
- Respect newline with pre-line but not for bullets to improve
formatting of responses by Khoj
- Respect bold font by loading tajawal font with other weights
- Reduce bottom margin in chat message bubble, its taking too much space
* Document original query when subqueries can't be generated
* Only add messages to the chat message log if it's non-empty
* When changing the search model, alert the user that all underlying data will be deleted
* Adding more clarification to the prompt input for username, location
* Check if has_more is in the notion results before getting next_cursor
* Update prompt template for user name/location, update confirmation message when changing search model
* Display given_name field only if it is not None
* Add default slugs in the migration script
* Ensure that updated_at is saved appropriately, make sure most recent chat is returned for default history
* Remove the bin button from the chat interface, given deletion is handled in the drop-down menus
* Refresh the side panel when a new chat is created
* Improveme tool retrieval prompt, don't let /online fail, and improve parsing of extract questions
* Fix ending chat response by offline chat on hitting a stop phrase
Previously the whole phrase wouldn't be in the same response chunk, so
chat response wouldn't stop on hitting a stop phrase
Now use a queue to keep track of last 3 chunks, and to stop responding
when hit a stop phrase
* Make chat on Obsidian backward compatible post chat session API updates
- Make chat on Obsidian get chat history from
`responseJson.response.chat' when available (i.e when using new api)
- Else fallback to loading chat history from
responseJson.response (i.e when using old api)
* Fix detecting success of indexing update in khoj.el
When khoj.el attempts to index on a Khoj server served behind an https
endpoint, the success reponse status contains plist with certs. This
doesn't mean the update failed.
Look for :errors key in status instead to determine if indexing API
call failed. This fixes detecting indexing API call success on the
Khoj Emacs client, even for Khoj servers running behind SSL/HTTPS
* Fix the mechanism for populating notes references in the conversation primer for both offline and online chat
* Return conversation.default when empty list for dynamic prompt selection, send all cmds in telemetry
* Fix making chat on Obsidian backward compatible post chat session API updates
New API always has conversation_id set, not `chat' which can be unset
when chat session is empty.
So use conversation_id to decide whether to get chat logs from
`responseJson.response.chat' or `responseJson.response' instead
---------
Co-authored-by: Debanjum Singh Solanky <debanjum@gmail.com>
- Remove unused git dependency from Docker images
- Move python packages used for test into dev dependency group
- Only enable API token, Whatsapp cards on Web UI when Stripe, Twilio setup
- Move production dependencies to prod python packages group
- Fix docs links in Khoj welcome chat message
This will reduce khoj dependencies to install for self-hosting users
- Move auth production dependencies to prod python packages group
- Only enable authentication API router if not in anonymous mode
- Improve error with requirements to enable authentication when not in
anonymous mode
* Add location metadata to chat history
* Add support for custom configuration of the user name
* Add region, country, city in the desktop app's URL for context in chat
* Update prompts to specify user location, rather than just location.
* Add location data to Obsidian chat query
* Use first word for first name, last word for last name when setting profile name
* Have Khoj dynamically select which conversation command(s) are to be used in the chat flow
- Intercept the commands if in default mode, and have Khoj dynamically guess which tools would be the most relevant for answering the user's query
* Remove conditional for default to enter online search mode
* Add multiple-tool examples in the prompt, make prompt for tools more specific to info collection
* Add chat sessions to the desktop application
* Increase width of the main chat body to 90vw
* Update the version of electron
* Render the default message if chat history fails to load
* Merge conversation migrations and fix slug setting
* Update the welcome message, use the hostURL, and update background color for chat actions
* Only update the window's web contents if the page is config
* Enable support for multiple chat sessions within the web client
- Allow users to create multiple chat sessions and manage them
- Give chat session slugs based on the most recent message
- Update web UI to have a collapsible menu with active chats
- Move chat routes into a separate file
* Make the collapsible side panel more graceful, improve some styling elements of the new layout
* Support modification of the conversation title
- Add a new field to the conversation object
- Update UI to add a threedotmenu to each conversation
* Get the default conversation if a matching one is not found by id
- Removed node-fetch dependency to work on mobile.
- Fix CORS issue for Khoj (streaming) chat on Obsidian mobile
- Verified Khoj plugin, search, chat work on Obsidian mobile.
## Details
### Major
- Allow calls to Khoj server from Obsidian mobile app to fix CORS issue
- Chat stream using default `fetch' not `node-fetch' in obsidian plugin
### Minor
- Load chat history after other elements in chat modal on Obsidian are rendered
- Scroll to bottom of chat modal on Obsidian across mobile & desktop
- Provide more context and instructions to offline chat on Khoj
- Upgrade offilne chat quality tests to support more use-cases
### Details
- Improve offline chat system prompt to think step by step
- Make offline chat model current date aware. Improve system prompts
- Fix actor, director tests using freeze time by ignoring transformers package
- Obsidian mobile uses capacitor js. Requests from it have origin as
http://localhost on Android and capacitor://localhost on iOS
- Allow those Obsidian mobile origins in CORS middleware of server
- Can now expect date awareness chat quality test to pass
- Prevent offline chat model from printing verbatim user Notes and
special tokens
- Make it ask follow-up questions if it needs more context
This allows using open or commerical, local or hosted LLM models that
are not supported in Khoj by default.
It also allows users to use other local LLM API servers that support
their GPU
Closes#407
- Put Whatsapp card back in Client section.
- Fixes side spacing on cards
- Improve Whatsapp card row gaps
- Hide notification banner on web app load. Previously it showed up as
a yellow dot on smaller displays
* Fix subscription state detection for users based on phone numbers, emails
* Fix unit tests for api_user4
* Use a single method for determining subscription from user
* Pass user object, rather than user.email for getting subscription state
* Fix license in pyproject.toml. Remove unused utils.state import
* Use single debug mode check function. Disable telemetry in debug mode
- Use single logic to check if khoj is running in debug mode.
Previously there were 3 different variants of the check
- Do not log telemetry if KHOJ_DEBUG is set to true. Previously didn't
log telemetry even if KHOJ_DEBUG set to false
* Respect line breaks in user, khoj chat messages to improve formatting
* Disable Whatsapp config section on web client if Twilio not configured
Simplify Whatsapp configuration status checking js by standardizing
external input to lower case
* Disable Phone API when Twilio not setup and rate limit calls to it
- Move phone api to separate router and only enable it if Twilio enabled
- Add rate-limiting to OTP and verification calls
* Add slugs for phone rate limiting
---------
Co-authored-by: sabaimran <narmiabas@gmail.com>
* Add a page about privacy and organize some of the documentation
* Add notice about telemetry
* Improve copy for privacy section, link to telemetry section
* Store rate limiter-related metadata in the database for more resilience
- This helps maintain state even between server restarts
- Allows you to scale up workers on your service without having to implement sticky routing
* Make the usage exceeded message less abrasive
* Fix rate limiter for specific conversation commands and improve the copy
* Add retries in case the embeddings API fails
* Improve error handling in the inference endpoint API request handler
- retry only if HTTP exception
- use logger to output information about errors
* Initailize changes to incporate web scraping logic after getting SERP results
- Do some minor refactors to pass a symptom prompt to the openai model when making a query
- integrate Olostep in order to perform the webscraping
* Fix truncation error with new line, fix typing in olostep code
* Use the authorization header for the token
* Add a small hint/indicator for how to use Khojs other modalities in the welcome prompt
* Add more detailed error message if Olostep query fails
* Add unit tests which invoke Olostep in chat director
* Add test for olostep tool
* Improve subqueries for online search and prompt generation for image
- Include conversation history so that subqueries or intermediate prompts are generated with the appropriate context
* Allow users to configure phone numbers with the Khoj server
* Integration of API endpoint for updating phone number
* Add phone number association and OTP via Twilio for users connecting to WhatsApp
- When verified, store the result as such in the KhojUser object
* Add a Whatsapp.svg for configuring phone number
* Change setup hint depending on whether the user has a number already connected or not
* Add an integrity check for the intl tel js dependency
* Customize the UI based on whether the user has verified their phone number
- Update API routes to make nomenclature for phone addition and verification more straightforward (just /config/phone, etc).
- If user has not verified, prompt them for another verification code (if verification is enabled) in the configuration page
* Use the verified filter only if the user is linked to an account with an email
* Add some basic documentation for using the WhatsApp client with Khoj
* Point help text to the docs, rather than landing page info
* Update messages on various callbacks and add link to docs page to learn more about the integration
## Major
### Move to single click audio chat UX on Obsidian, Desktop, Web clients
New default UX has 1 long-press on mobile, 2-click on desktop to send transcribed audio message
- New Audio Chat Flow
1. Record audio while microphone button pressed
2. Show auto-send 3s countdown timer UI for audio chat message
Provide a visual cue around send button for how long before audio
message is automatically sent to Khoj for response
3. Auto-send msg in 3s unless stop send message button clicked
- Why
- Removes the previous default of 3 clicks required to send audio message
The record > stop > send process to send audio messages was unclear and effortful
- Still allows stopping message from being sent, to make correction to transcribed audio
- Removes inadvertent long audio transcriptions if forget to press stop while recording
### Improve chat input pane actions & icons on Obsidian. Desktop, Web clients
- Use SVG icons in chat footer on web, desktop app
- Move delete icon to left of chat input. This makes it harder to inadvertently click it
- Add send button to chat input pane
- Color chat message send button to make it primary CTA
- Make chat footer shorter. Use no or round border on action buttons
## Minor
- Stop rendering empty starter questions element when no questions present
- Add round border, hover color to starter questions in web, desktop apps
- Fix auto resizing chat input box when transcribed text added
- Convert chat input into a text area in the Obsidian client
- Capabillity
New default UX has 1 long-press to send transcribed audio message
- Removes the previous default of 3 clicks required to send audio message
- The record > stop > send process to send audio messages was unclear
- Still allows stopping message from being sent, if users want to make
correction to transcribed audio
- Removes inadvertent long audio transcriptions if user forgets to
press stop when recording
- Changes
- Record audio while microphone button pressed
- Show auto-send 3s countdown timer UI for audio chat message
Provide a visual cue around send button for how long before audio
message is automatically sent to Khoj for response
- Auto-send msg in 3s unless stop send message button clicked
- Capabillity
New default UX has 1 long-press to send transcribed audio message
- Removes the previous default of 3 clicks required to send audio message
- The record > stop > send process to send audio messages was unclear
- Still allows stopping message from being sent, if users want to make
correction to transcribed audio
- Removes inadvertent long audio transcriptions if user forgets to
press stop when recording
- Changes
- Record audio while microphone button pressed
- Show auto-send 3s countdown timer UI for audio chat message
Provide a visual cue around send button for how long before audio
message is automatically sent to Khoj for response
- Auto-send msg in 3s unless stop send message button clicked
- Capabillity
New default UX has 1 long-press to send transcribed audio message
- Removes the previous default of 3 clicks required to send audio message
- The record > stop > send process to send audio messages was unclear
- Still allows stopping message from being sent, if users want to make
correction to transcribed audio
- Removes inadvertent long audio transcriptions if user forgets to
press stop when recording
- Changes
- Record audio while microphone button pressed
- Show auto-send 3s countdown timer UI for audio chat message
Provide a visual cue around send button for how long before audio
message is automatically sent to Khoj for response
- Auto-send msg in 3s unless stop send message button clicked
- Move delete icon to left of chat input. This makes it harder to
inadvertently click
- Add send button to chat footer. Enter being the only way to send
messages is not intuitive, outside standard modern UI patterns
- Color chat message send button to make it primary CTA on web client
- Make chat footer shorter. Use no or round border on action buttons
- Use SVG icons in chat footer on web
- Move delete icon to left of chat input. This makes it harder to
inadvertently click
- Add send button to chat footer. Enter being the only way to send
messages is not intuitive, outside standard modern UI patterns
- Color chat message send button to make it primary CTA on web client
- Make chat footer shorter. Use no or round border on action buttons
- Use SVG icons in chat footer on web
- Move delete icon to left of chat input. This makes it harder to
inadvertently click
- Add send button to chat footer. Enter being the only way to send
messages is not intuitive, outside standard modern UI patterns
- Color chat message send button to make it primary CTA on web client
- Make chat footer shorter. Use no or round border on action buttons
* Add support for a first party client app
- Based on a client id and client secret, allow a first party app to call into the Khoj backend with a phone number identifier
- Add migration to add phone numbers to the KhojUser object
* Add plus in front of country code when registering a phone number.
- Decrease free tier limit to 5 (from 10)
- Return a response object when handling stripe webhooks
* Fix telemetry method which references authenticated user's client app
* Add better error handling for null phone numbers, simplify logic of authenticating user
* Pull the client_secret in the API call from the authorization header
* Add a migration merge to resolve phone number and other changes
The actual issue was that `get_or_create_user_by_email' tried to
create a subscription even if it already existed.
With updated logic:
- New subscription is only created when it doesn't already exist in
`get_or_create_user_by_email'
- `set_user_subscription' just updates the subscription state as
user subscription object creation is already managed by
`get_or_create_user_by_email'. So the other conditionals are
unnecessary
- Issue
Users with Dataview plugin would have error as its markdown
post-processor expects the sourcePath to be a string
This prevents Khoj from responding to chat messages in the Obsidian
chat modal. Search via Obsidian still works but it throws the same
dataview plugin error
- Fix
Pass a string as sourcePath to markdownRenderer to fix failing chat response
and stop throwing dataview errors on search
Resolves#614, Resolves#606
- Update health API to pass authenticated users their info
- Improve Khoj server status check in Khoj Obsidian client
- Show Khoj Obsidian commands even if no connection to server
- Show Khoj chat by default in Obsidian side pane instead of search
Server connection check can be a little flaky in Obsidian. Don't gate
the commands behind it to improve usability of Khoj.
Previously the commands would get disabled when server connection
check failed, even though server was actually accessible
- Update server connection status on every edit of khoj url, api key in
settings instead of only on plugin load
The error message was stale if connection fixed after changes in
Khoj plugin settings to URL or API key, like on plugin install
- Show better welcome message on first plugin install.
Include API key setup instruction
- Show logged in user email on Khoj settings page
- Issue: Users with Dataview plugin would have error as its markdown
post-processor expects the sourcePath to be a string
This prevents Khoj from responding to chat messages in the Obsidian
chat modal. Search via Obsidian still works but it throws the same
dataview error
- Fix: Pass a string as sourcePath to markdownRenderer to fix
failing chat response
Resolves#614, Resolves#606
* Add support for custom inference endpoints for the cross encoder model
- Since there's not a good out of the box solution, I've deployed a custom model/handler via huggingface to support this use case.
* Use langchain.community for pdf, openai chat modules
* Add an explicit stipulation that the api endpoint for crossencoder inference should be for huggingface for now
This allows Khoj clients to get email address associated with
user's API token for display in client UX
In anonymous mode, default user information is passed
### Major
- Short-circuit API rate limiter for unauthenticated user
Calls by unauthenticated users were failing at API rate limiter as it
failed to access user info object. This is a bug.
API rate limiter should short-circuit for unauthenicated users so a
proper Forbidden response can be returned by API
Add regression test to verify that unauthenticated users get 403
response when calling the /chat API endpoint
### Minor
- Remove trailing slash to normalize khoj url in obsidian plugin settings
- Move used /api/config API controllers into separate module
- Delete unused /api/beta API endpoint
- Fix error message rendering in khoj.el, khoj obsidian chat
- Handle deprecation warnings for subscribe renew date, langchain, pydantic & logger.warn
- Use /api/health for server up check instead of api/config/default
- Remove unused `khoj--post-new-config' method
- Remove the now unused /config/data GET, POST API endpoints
### Major
- Push 1000 files at a time from the Desktop client for indexing
- Push 1000 files at a time from the Obsidian client for indexing
- Test 1000 file upload limit to index/update API endpoint
### Minor
- Show relevant error message in desktop app, e.g when can't connect to server
- Pass indexed filenames in API response for client validation
- Collect files to index in single dict to simplify index/update controller
Resolves#573
- Only run /online command offline chat director test when `SERPER DEV_API_KEY' present
- Decode URL encoded query string in chat API endpoint before processing
- Make references and online_results optional params to converse_offline
- Pass max context length to fix using updated `GPT4All.list_gpu' method
* Support using hosted Huggingface inference endpoint for embeddings generation
* Since the huggingface inference endpoint is model-specific, make the URL an optional property of the search model config
* Handle ECONNREFUSED error in desktop app
* Drive API key via the search model config model and use more generic names
- Ensure langchain less than 0.2.0 is used, to prevent breaking
ChatOpenAI, PyMuPDF usage due to their deprecation after 0.2.0
- Set subscription renewal date to a timezone aware datetime
- Use logger.warning instead of logger.warn as latter is deprecated
- Use `model_dump' not deprecated dict to get all configured content_types
Calls by unauthenticated users were failing at API rate limiter as it
failed to access user info object. This is a bug.
API rate limiter should short-circuit for unauthenicated users so a
proper Forbidden response can be returned by API
Add regression test to verify that unauthenticated users get 403
response when calling the /chat API endpoint
FastAPI API endpoints only support uploading 1000 files at a time.
So split all files to index into groups of 1000 for upload to
index/update API endpoint
- 26f96e00 Use Khoj Client, Data sources diagrams in feature docs
- c82d34b6 Add Docs footer, nav pane links. Fix tagline, Remove announcement topbar
- d920e4d0 Make the docs overview page as the main docs landing page
- 80d1ad5b Fix image urls on docs overview page. Remove logo header in client docs
- Make the docs overview page available at docs.khoj.dev root instead of
under docs.khoj.dev/docs path
- Remove the new landing page, it is unnecessary.
- Remove /docs path prefix from links to internal doc pages
- Remove .md path suffix in internal doc pages for consistency
FastAPI API endpoints only support uploading 1000 files at a time.
So split all files to index into groups of 1000 for upload to
index/update API endpoint
Make usage of the first offline/openai chat model as the default LLM
to use for background tasks more explicit
The idea is to use the default/first chat model for all background
activities, like user message to extract search queries to perform.
This is controlled by the server admin.
The chat model set by the user is used for user-facing functions like
generating chat responses
Previously you could only index org-mode files and directories from
khoj.el
Mark the `khoj-org-directories', `khoj-org-files' variables for
deprecation, since `khoj-index-directories', `khoj-index-files'
replace them as more appropriate names for the more general case
Resolves#597
- Add more accurate steps for building Khoj locally
- Remove outdated instructions
- Add specific steps to create a Github Issue
- Add instructions for Obsidian plugin development
- Fix streaming chat response in Obsidian client
- Fix first-run, chat error message in obsidian, desktop and web clients
- Set Khoj app version to latest version in Docker images
- Tag Khoj Docker image built on release with the `latest` tag
This align docker image release cadence with client, server releases
- Tag docker image with `tag_name' on release (i.e tag push)
- Else tag with 'pre' on push to master
- Else tag with 'dev' on push to PR branch
- Only tag the latest release with release tag
Previously the latest commit on master was being tagged with the
latest tag. This doesn't sync with the release cadence of the rest
of Khoj
This will allow troubleshooting by getting the actual khoj version
being used. Previously it was always set to a static 0.0.0 version
Command to build Khoj docker image with dynamically set current app version:
`docker-compose build server --build-arg VERSION=$(pipx run hatch version)'
- Honor this setting across the relevant places where embeddings are used
- Convert the VectorField object to have None for dimensions in order to make the search model easily configurable
- Improve the prompt before sending it for image generation
- Update the help message to include online, image functionality
- Improve styling for the voice, trash buttons
The source URL returned by OpenAI would expire soon. This would make
the chat sessions contain non-accessible images/messages if using
OpenaI image URL
Get base64 encoded image from OpenAI and store directly in
conversation logs. This resolves the image link expiring issue
- All search models are loaded into memory, and stored in a dictionary indexed by name
- Still need to add database migrations and create a UI for user to select their choice. Presently, it uses the default option
- Move it out to conversation.utils from generate_chat_response function
- Log new optional intent_type argument to capture type of response
expected. This can be type responses by Khoj e.g speech, image. It
can be used to render responses by Khoj appropriately on clients
- Make user_message_time argument optional, set the time to now by
default if not passed by calling function
- Wasn't able to login to the admin panel when KHOJ_DEBUG was not True. Fix this error so self-hosted users can get unblocked from accessing the admin settings
- Don't force users to set their KHOJ_DJANGO_SECRET_KEY
- Show temporary status message when copied to clipboard
- Render chat responses as markdown in Desktop client
- Render chat responses as markdown in chat modal of Obsidian client
- Render references of new responses in chat modal on Obsidian client. Use new style for references
- Properly stop `mediaRecorder` stream to clear microphone in-use state
- Render newlines when references expanded in Web, Desktop and Obsidian clients
- Use new style references for Khoj chat modal in Obsidian
- Khoj Chat responses in Obsidian had regressed to not show references
for new questions after modal has been opened. Now even those are
rendered, and use new references style
- Render chat response as markdown while it's being streamed
- Create speech to text API endpoint
- Use OpenAI Whisper for ASR offline (by downloading Whisper model) or online (via OpenAI API)
- Add speech to text model configuration to Database
- Speak to Khoj from the Web, Desktop or Obsidian client
- Add transcription button with mic icon
- Collect audio recording on pressing mic
- Process and send audio recording to server for transcription
- Extract the functionality to flash status in chat input for reuse
- Allow server admin to configure offline speech to text model during
initialization
- Use offline speech to text model to transcribe audio from clients
- Set offline whisper as default speech to text model as no setup api key reqd
- Extract flashing status message in chat input placeholder into
reusable function
- Use emoji prefixes for status messages
- Improve alt text of transcribe button to indicate what the button does
- Conflicts:
- src/interface/desktop/chat.html
Combine and use common class names for speak component
- src/khoj/database/adapters/__init__.py
Combine imports
- src/khoj/interface/web/chat.html
Combine and use common class names for speak component
- src/khoj/routers/api.py
Combine imports
- Add a dependency on the indexer API endpoint that rounds up the amount of data indexed and uses that to determine whether the next set of data should be processed
- Delete any files that are being removed for adminstering the calculation
- Show current amount of data indexed in the config page
- Ignore errors in deleting network requests to khoj server
- Also delete open network connection to khoj server on auto reindex
Otherwise when server is unreachable a bunch of failed network
connections accrue in the processes list
- Make auto-update of content index user configurable from khoj.el
- Handle server unavailable error on auto-index schedule job in khoj.el
Resolves#567
- Append chat message to chat logs as TextNodes in web, desktop clients
- Simplify Code to Identify Files from Github, Notion on Web, Desktop Client
- Use file source to find entries from github, notion on web, desktop client
- Pass file source to clients via text search API response
- Make Django Logs Follow Khoj Log Format, Verbosity
- Handle image search setup related warning
- Format Django initializing outputs using Khoj logger format
- Use `KHOJ_HOST` env var to set allowed/trusted domains to host Khoj
Ideally should rename model_directory to config_directory or some such
but the current image search code will need to be migrated soon. So
changing the variable name and creating a migration script for old
khoj.yml files using model-directory variable isn't worth it
Remove the explicity set of number of threads to use by pytorch. Use
the default used by it.
- Collect STDOUT from the `migrate', `collectstatic' commands and
output using the Khoj logger format and verbosity settings
- Only show Django `collectstatic' command output in verbose mode
- Fix showing the Initializing Khoj log line by moving it after logger
level set
This bug was causing the search results on the Obsidian client to be shown in the reverse order of their actual relevance.
It reversed since entry scores returned by Khoj server are a distance metric since the move to Postgres. So lesser distance is better. Previously higher score was better.
Previously it was only searching for PDF and Markdown files. This was
meant to show only content from current vault as results.
But it has not scaled well as other clients also allow syncing PDF and
markdown files now. So remove this content type filter for now.
A proper solution would limit by using file/dir filters on server or
client side.
- PyPi doesn't like to have files that start with numbers, however all of the generated django migration files start with numbers. To accommodate, skip this check.
- Refer to https://pypi.org/project/check-wheel-contents/ for documentation and recommendation
- Our pypi package currently does not work because the django app and associated database is not included. To remedy this issue, move the app into the src/khoj folder. This has the added benefit of improved organization of the codebase, as all server related code is now in a single folder
- Update associated file paths and system references
- c07401cf Fix, Improve chat config via CLI on first run by using defaults
- d61b0dd5 Add Khoj Django app package to sys path to load Django module via pip install
- 4e98acbc Update minimum pydantic version to one with model_validate function
### Overview
The parent hierarchy of org-mode entries can store important context.
This change updates OrgNode to track parent headings for each org entry and adds the parent outline for each entry to the index
### Details
- Test search uses ancestor headings as context for improved results
- Add ancestor headings of each org-mode entry to their compiled form
- Track ancestor headings for each org-mode entry in org-node parser
Resolves#85
- Update docs to show how to use Khoj Cloud
- Move self-hosting Khoj to separate section
- Add page to setup Desktop app
- Set default URL to Khoj Cloud URL in Obsidian, Emacs clients
- No Khoj server setup required to start using Khoj from Obsidian, Emacs
- Use tabs for install, upgrade in Emacs with different package
managers
- Use default subtitles in Khoj Docs
- Deduplicate query filters, remove backend setup instructions in
plugin pages
- Remove stale Setup demo on Khoj Obsidian plugin docs
- Upgrade FastAPI to >= latest version. Required upgrade of FastAPI.
Earlier version didn't support wrapping common query params in class
- Use per fixture app instead of a global FastAPI app in conftest
- Upgrade minimum required Django version
- Fix no notes chat director test with updated no notes message
No notes message was updated in commit 118f1143
- Use the knowledgeGraph, answerBox, peopleAlsoAsk and organic responses of serper.dev to provide online context for queries made with the /online command
- Add it as an additional tool for doing Google searches
- Render the results appropriately in the chat web window
- Pass appropriate reference data down to the LLM
- By default assume the audience of this website is people looking to understand the featuer offering of Khoj, and then people who are looking to self-host
- Most important updates include the depedency requirement to setup Postgres when running/setting Khoj up locally
- Add instructiosn for Docker
- Shift to recommend desktop client and update instructions for how to configure Khoj for user
- Adds support for multiple users to be connected to the same Khoj instance using their Google login credentials
- Moves storage solution from in-memory json data to a Postgres db. This stores all relevant information, including accounts, embeddings, chat history, server side chat configuration
- Adds the concept of a Khoj server admin for configuring instance-wide settings regarding search model, and chat configuration
- Miscellaneous updates and fixes to the UX, including chat references, colors, and an updated config page
- Adds billing to allow users to subscribe to the cloud service easily
- Adds a separate GitHub action for building the dockerized production (tag `prod`) and dev (tag `dev`) images, separate from the image used for local building. The production image uses `gunicorn` with multiple workers to run the server.
- Updates all clients (Obsidian, Emacs, Desktop) to follow the client/server architecture. The server no longer reads from the file system at all; it only accepts data via the indexer API. In line with that, removes the functionality to configure org, markdown, plaintext, or other file-specific settings in the server. Only leaves GitHub and Notion for server-side configuration.
- Changes license to GNU AGPLv3
Resolves#467Resolves#488Resolves#303Resolves#345Resolves#195Resolves#280Resolves#461Closes#259Resolves#351Resolves#301Resolves#296
- Update test data to add deeper outline hierarchy for testing
hierarchy as context
- Update collateral tests that need count of entries updated, deleted
asserts to be updated
- Make search model configurable on server
- Update migration script to get search model from `khoj.yml` to Postgres
- Update first run message on Khoj Desktop and Web app landing page
- Other miscellaneous bug fixes
- Link to Django admin panel for user to create Chat Models on their
Khoj server
- This should only get hit when user is not using Khoj cloud, as Khoj
cloud would already have Chat models configured
- While sigmoid normalization isn't required for reranking.
Normalizing score to distance metrics for both encoder and cross
encoder scores is useful to reason about them
- Softmax wasn't required as don't need probabilities, sigmoid is good
enough to get distance metric
- Expose ability to modify search model via Django admin interface
- Previously the bi_encoder and cross_encoder models to use were set
in code
- Now it's user configurable but with a default config generated by
default
### Overview
Prepare Khoj with multi-user, db support for Khoj Cloud release
### Details
- Add first run experience to configure Khoj via khoj CLI
- Improve Web app settings page: Move files data into content section card. Move content index update button(s) to content section
- Improve OpenAI chat prompts
- Push more general information for OpenAI models into system prompt
- Make it more aware of it's current capabilities
- Weaken asking follow-up questions
- Rate-limit calls to the chat API
- Add back search results quality threshold
- Normalize quality score definitions across cross_encoder, encoder to distance metric
- Remove reference to deprecated button
- Await result of the search query
- Fixed Langchain issue by allowing the Docker image to rebuild with a later package version
- During the migration, the confidence score stopped being used. It
was being passed down from API to some point and went unused
- Remove score thresholding for images as image search confidence
score different from text search model distance score
- Default score threshold of 0.15 is experimentally determined by
manually looking at search results vs distance for a few queries
- Use distance instead of confidence as metric for search result quality
Previously we'd moved text search to a distance metric from a
confidence score.
Now convert even cross encoder, image search scores to distance metric
for consistent results sorting
Remove the Results Count button from the web app. It's hanging weirdly
with not much context to its purpose.
Reintroduce it in the Search card when created under the Features section
Reduce user confusion by joining config update with index updation for
each content type.
So only a single click required to configure any content type instead
of two clicks on two separate pages
- Notes prompt doesn't need to be so tuned to question answering. User
could just want to talk about life. The notes need to be used to
response to those, not necessarily only retrieve answers from notes
- System and notes prompts were forcing asking follow-up questions a
little too much. Reduce strength of follow-up question asking
The Chat models sometime output reference notes directly in the chat
body in unformatted form, specifically as Notes:\n['. Prevent that.
Reference notes are shown in clean, formatted form anyway
- Show next sync time to make users aware of data sync is automated
- Keep a single Save button to reduce confusion. It does what Save All
previously did. Intent to manual sync should Save All
- Default to using app.khoj.dev as default Khoj URL to ease Cloud sync setup
- Add detailed chat intro message, mention download desktop app for docs sync
- Only show search in web app nav pane if user has documents indexed
- Hide download desktop app message in web app if synced files exist
- Mark generated profile pic with subscription circle in web app
- Make mutable syncing variable not a const
- Show next sync time to make users aware of data sync is automated
- Keep a single Save button to reduce confusion. It does what Save All
previously did. Intent to manual sync should Save All
- Default to using app.khoj.dev as default Khoj URL to ease setup
### Major
- Expose Billing via Stripe on Khoj Web app for Khoj Cloud subscription
- Expose card on web app config page to manage subscription to Khoj cloud
- Create API webhook, endpoints for subscription payments using Stripe
- Put Computer files to index into Card under Content section
- Show file type icons for each indexed file in config card of web app
- Enable deleting all indexed desktop files from Khoj via Desktop app
- Create config page on web app to manage computer files indexed by Khoj
- Track data source (computer, github, notion) of each entry
- Update content by source via API. Make web client use this API for config
- Store the data source of each entry in database
### Cleanup
- Set content enabled status on update via config buttons on web app
- Delete deprecated content config pages for local files from web client
- Rename Sync button, Force Sync toggle to Save, Save All buttons
### Fixes
- Prevent Desktop app triggering multiple simultaneous syncs to server
- Upgrade langchain version since adding support for OCR-ing PDFs
- Bubble up content indexing errors to notify user on client apps
- Add fields to mark users as subscribed to a specific plan and
subscription renewal date in DB
- Add ability to unsubscribe a user using their email address
- Expose webhook for stripe to callback confirming payment
Previously hitting configure or disable wouldn't update the state of
the content cards. It needed page refresh to see if the content was
synced correctly.
Now cards automatically get set to new state on hitting disable button
on card or global configure buttons
Lock syncing to server if a sync is already in progress.
While the sync save button gets disabled while sync is in progress,
the background sync job can still trigger a sync in parallel. This
sync lock prevents that
Remove the table of all files indexed by Khoj. This seems overkill and
doesn't match the UI semantics of the other data sources like Github,
Notion.
Create instead a data source card for computer files with the same
update, disable semantics of the Github and Notion data source cards
Users can disable each data source from its card on the main config page.
They can see/delete individual files indexed from the computer data source
once they click into the computer files data source card on the config page
This will be useful for updating, deleting entries by their data
source. Data source can be one of Computer, Github or Notion for now
Store each file/entries source in database
Major
- Ensure search results logic consistent across migration to DB, multi-user
- Manually verified search results for sample queries look the same across migration
- Flatten indexing code for better indexing progress tracking and code readability
Minor
- a4f407f Test memory leak on MPS device when generating vector embeddings
- ef24485 Improve Khoj with DB setup instructions in the Django app readme (for now)
- f212cc7 Arrange remaining text search tests in arrange, act, assert order
- 022017d Fix text search tests to test updated indexing log messages
The Langchain HuggingFaceEmbeddings wrapper doesn't support disabling
progressbar, not especially for only query but not documents.
This makes the logs noisy with encoding progressbar for each
incremental queries
No features of the Langchain wrapper for SentenceTransformer was
currently being used anyway for now, and we can always switch back to
it if required
Flatten the nested loops to improve visibilty into indexing progress
Reduce spurious logs, report the logs at aggregated level and update
the logging description text to improve indexing progress reporting
- Given the separation of the client and server now, the web UI will no longer support configuration of local file paths of data to index
- Expose a way to show all the files that are currently set for indexing, along with an option to delete all or specific files
- Update theme for Desktop, Web and Obsidian client apps to use lighter colors
- Show splash screen on starting Desktop app
- Make chat the landing page on Desktop and Web clients
- Simplify style of login page on Web app
- Add About page for Desktop app accessible from system tray menu
- Remove spurious whitespace in chat input box on page load being
added because text area element was ending on newline
- Do not insert newline in message when send message by hitting enter key
This would be more evident when send message with cursor in the
middle of the sentence, as a newline would be inserted at the cursor
point
- Remove chat message separator tokens from model output. Model
sometimes starts to output text in it's chat format
- Pass current khoj version from package.json to about page via
electron IPC between backend js and frontend page
- Update Khoj information in default About screen as well, in case
it's exposed anywhere else
- Update background color to a different shade of white
- Make primary and primary hover colors less intense and more aligned
with lantern flame shade
- Add water, leaf, flower color variables
Fix refactor bugs, CSRF token issues for use in production
* Add flags for samesite settings to enable django admin login
* Include tzdata to dependencies to work around python package issues in linux
* Use DJANGO_DEBUG flag correctly
* Fix naming of entry field when creating EntryDate objects
* Correctly retrieve openai config settings
* Fix datefilter with embeddings name for field
- Update background color to a different shade of white
- Make primary and primary hover colors less intense and more aligned
with lantern flame shade
- Add water, leaf, flower color variables
- Rather than having each individual user configure their conversation settings, allow the server admin to configure the OpenAI API key or offline model once, and let all the users re-use that code.
- To configure the settings, the admin should go to the `django/admin` page and configure the relevant chat settings. To create an admin, run `python3 src/manage.py createsuperuser` and enter in the details. For simplicity, the email and username should match.
- Remove deprecated/unnecessary endpoints and views for configuring per-user chat settings
### ✨ New
- Create profile pic drop-down menu in navigation pane
Put settings page, logout action under drop-down menu
### ⚙️ Fix
- Add Key icon for API keys table on Web Client's settings page
### 🧪 Improve
- Rename `TextEmbeddings` to `TextEntries` for improved readability
- Rename `Db.Models` `Embeddings`, `EmbeddingsAdapter` to `Entry`, `EntryAdapter`
- Show truncated API key for identification & restrict table width for config page responsiveness
Previously pico.css font-families were being selected for the config
page. This was different from the fonts used by index.html, chat.html
This improves spacing issue of heading further
- Create dropdown menu. Put settings page, logout action under it
- Make user's profile picture the dropdown menu heading
- Create khoj.js to store shared js across web client
It currently stores the dropdown menu open, close functionality
- Put shared styling for khoj dropdown menu under khoj.css
- Use a function to generate API Key table row HTML, to dedup logic
- Show delete, copy icon hints on hover
- Reduce length of copied message to not expand table width
- Truncating API key helps keep the API key table width within width
of smaller width displays
Emoji icons have already been added to the Search, Chat and Settings
top navigation menu in the desktop client. This change adds these to
the web client as well
Improves readability as name has closer match to underlying
constructs
- Entry is any atomic item indexed by Khoj. This can be an org-mode
entry, a markdown section, a PDF or Notion page etc.
- Embeddings are semantic vectors generated by the search ML model
that encodes for meaning contained in an entries text.
- An "Entry" contains "Embeddings" vectors but also other metadata
about the entry like filename etc.
- Add a productionized setup for the Khoj server using `gunicorn` with multiple workers for handling requests
- Add a new Dockerfile meant for production config at `ghcr.io/khoj-ai/khoj:prod`; the existing Docker config should remain the same
### ✨ New
- Use API keys to authenticate from Desktop, Obsidian, Emacs clients
- Create API, UI on web app config page to CRUD API Keys
- Create user API keys table and functions to CRUD them in Database
### 🧪 Improve
- Default to better search model, [gte-small](https://huggingface.co/thenlper/gte-small), to improve search quality
- Only load chat model to GPU if enough space, throw error on load failure
- Show encoding progress, truncate headings to max chars supported
- Add instruction to create db in Django DB setup Readme
### ⚙️ Fix
- Fix error handling when configure offline chat via Web UI
- Do not warn in anon mode about Google OAuth env vars not being set
- Fix path to load static files when server started from project root
- Add a data model which allows us to store Conversations with users. This does a minimal lift over the current setup, where the underlying data is stored in a JSON file. This maintains parity with that configuration.
- There does _seem_ to be some regression in chat quality, which is most likely attributable to search results.
This will help us with #275. It should become much easier to maintain multiple Conversations in a given table in the backend now. We will have to do some thinking on the UI.
- Make most routes conditional on authentication *if anonymous mode is not enabled*. If anonymous mode is enabled, it scaffolds a default user and uses that for all application interactions.
- Add a basic login page and add routes for redirecting the user if logged in
- Partition configuration for indexing local data based on user accounts
- Store indexed data in an underlying postgres db using the `pgvector` extension
- Add migrations for all relevant user data and embeddings generation. Very little performance optimization has been done for the lookup time
- Apply filters using SQL queries
- Start removing many server-level configuration settings
- Configure GitHub test actions to run during any PR. Update the test action to run in a containerized environment with a DB.
- Update the Docker image and docker-compose.yml to work with the new application design
- Offline chat models outputing gibberish when loaded onto some GPU.
GPU support with Vulkan in GPT4All seems a bit buggy
- This change mitigates the upstream issue by allowing user to
manually disable using GPU for offline chat
Closes#516
GPT4all now supports gguf llama.cpp chat models. Latest
GPT4All (+mistral) performs much at least 3x faster.
On Macbook Pro at ~10s response start time vs 30s-120s earlier.
Mistral is also a better chat model, although it hallucinates more
than llama-2
Ignore .org, .pdf etc. suffixed directories under `input-filter' from
being evaluated as files.
Explicitly filter results by input-filter globs to only index files,
not directory for each text type
Add test to prevent regression
Closes#448
On Windows, the default locale isn't utf8. Khoj had regressed to
reading files in OS specified locale encoding, e.g cp1252, cp949 etc.
It now explicitly uses utf8 encoding to read text files for indexing
Resolves#495, resolves#472
* Changed globbing. Now doesn't clobber a users glob if they want to add it, but will (if just given a directory), add a recursive glob.
Note: python's glob engine doesn't support `{}` globing, a future option is to warn if that is included.
* Fix typo in globformat variable
* Use older glob pattern for plaintext files
---------
Co-authored-by: Saba <narmiabas@gmail.com>
### Overview
- Add ability to push data to index from the Emacs, Obsidian client
- Switch to standard mechanism of syncing files via HTTP multi-part/form. Previously we were streaming the data as JSON
- Benefits of new mechanism
- No manual parsing of files to send or receive on clients or server is required as most have in-built mechanisms to send multi-part/form requests
- The whole response is not required to be kept in memory to parse content as JSON. As individual files arrive they're automatically pushed to disk to conserve memory if required
- Binary files don't need to be encoded on client and decoded on server
### Code Details
### Major
- Use multi-part form to receive files to index on server
- Use multi-part form to send files to index on desktop client
- Send files to index on server from the khoj.el emacs client
- Send content for indexing on server at a regular interval from khoj.el
- Send files to index on server from the khoj obsidian client
- Update tests to test multi-part/form method of pushing files to index
#### Minor
- Put indexer API endpoint under /api path segment
- Explicitly make GET request to /config/data from khoj.el:khoj-server-configure method
- Improve emoji, message on content index updated via logger
- Don't call khoj server on khoj.el load, only once khoj invoked explicitly by user
- Improve indexing of binary files
- Let fs_syncer pass PDF files directly as binary before indexing
- Use encoding of each file set in indexer request to read file
- Add CORS policy to khoj server. Allow requests from khoj apps, obsidian & localhost
- Update indexer API endpoint URL to` index/update` from `indexer/batch`
Resolves#471#243
New URL query params, `force' and `t' match name of query parameter in
existing Khoj API endpoints
Update Desktop, Obsidian and Emacs client to call using these new API
query params. Set `client' query param from each client for telemetry
visibility
New URL follows action oriented endpoint naming convention used for
other Khoj API endpoints
Update desktop, obsidian and emacs client to call this new API
endpoint
Using fetch from Khoj Obsidian plugin was failing due to cross-origin
request and method: no-cors didn't allow passing x-api-key custom
header. And using Obsidian's request with multi-part/form-data wasn't
possible either.
- Keep state of previously synced files to identify files to be deleted
- Last synced files stored in settings for persistence of this data
across Obsidian reboots
Use the multi-part/form-data request to sync Markdown, PDF files in
vault to index on khoj server
Run scheduled job to push updates to value for indexing every 1 hour
This prevents Khoj from polling the Khoj server until explicitly
invoked via `khoj' entrypoint function.
Previously it'd make a request to the khoj server every time Emacs or
khoj.el was loaded
Closes#243
Previously lookback turns was set to a static 2. But now that we
support more chat models, their prompt size vary considerably.
Make lookback_turns proportional to max_prompt_size. The truncate_messages
can remove messages if they exceed max_prompt_size later
This lets Khoj pass more of the chat history as context for models
with larger context window
- Dedupe offline_chat_model variable. Only reference offline chat
model stored under offline_chat. Delete the previous chat_model
field under GPT4AllProcessorConfig
- Set offline chat model to use via config/offline_chat API endpoint
This provides flexibility to use non 1st party supported chat models
- Create migration script to update khoj.yml config
- Put `enable_offline_chat' under new `offline-chat' section
Referring code needs to be updated to accomodate this change
- Move `offline_chat_model' to `chat-model' under new `offline-chat' section
- Put chat `tokenizer` under new `offline-chat' section
- Put `max_prompt' under existing `conversation' section
As `max_prompt' size effects both openai and offline chat models
Pass user configured chat model as argument to use by converse_offline
The proper fix for this would allow users to configure the max_prompt
and tokenizer to use (while supplying default ones, if none provided)
For now, this is a reasonable start.
- Format extract questions prompt format with newlines and whitespaces
- Make llama v2 extract questions prompt consistent
- Remove empty questions extracted by offline extract_questions actor
- Update implicit qs extraction unit test for offline search actor
* Strip the incoming query from the slash conversation command before passing it to the model or for search
* Return q when content index not loaded
* Remove -n 4 from pytest ini configuration to isolate test failures
- Make `bump_version.sh' script set version for the Khoj desktop app too
- Sync Khoj desktop app authors, license, description and version with
the other interfaces and server
- Update description in packages metadata to match project subtitle on Github
- Pass payloads as unibyte. This was causing the request to fail for
files with unicode characters
- Suppress messages with file content in on index updates
- Fix rendering response from server on index update API call
- Extract code to populate body of index update HTTP request with files
Previously global state of `url-request-method' would affect the
kind of request made to api/config/data API endpoint as it wasn't
being explicitly being set before calling the API endpoint
This was done with the assumption that the default value of GET for
url-request-method wouldn't change globally
But in some cases, experientially, it can get changed. This was
resulting in khoj.el load failing as POST request was being made
instead which would throw error
Instead of using the previous method to push data as json payload of POST request
pass it as files to upload via the multi-part/form to the batch indexer API endpoint
- Add elisp variable to set API key to engage with the Khoj server
- Use multi-part form to POST the files to index to the indexer API
endpoint on the khoj server
Previously only the the last filter's terms were getting effectively
applied as the `filter.defilter' operation was being done on
`user_query' but was updating the `defiltered_query'
- This uses existing HTTP affordance to process files
- Better handling of binary file formats as removes need to url encode/decode
- Less memory utilization than streaming json as files get
automatically written to disk once memory utilization exceeds preset limits
- No manual parsing of raw files streams required
Use mailbox closed with flag down once content index completed.
Use standard, existing logger messages in new indexer messages, when
files to index sent by clients
- Improves user experience by aligning idle time with search latency
to avoid display jitter (to render results) while user is typing
- Makes the idle time configurable
Closes#480
* Use separate functions for adding files and folders to configuration for indexing
* Add a loading bar while data is syncing
* Bump the minor version for the application
We are always looking for contributors to help us build new features, improve the project documentation, or fix bugs. If you're interested, please see our [Contributing Guidelines](https://docs.khoj.dev/contributing/development) and check out our [Contributors Project Board](https://github.com/orgs/khoj-ai/projects/4).
# Use the following line to use the latest version of khoj. Otherwise, it will build from source.
image:ghcr.io/khoj-ai/khoj:latest
# Uncomment the following line to build from source. This will take a few minutes. Comment the next two lines out if you want to use the offiicial image.
# build:
# context: .
ports:
# If changing the local port (left hand side), no other changes required.
# If changing the remote port (right hand side),
@@ -10,24 +31,27 @@ services:
- "42110:42110"
working_dir:/app
volumes:
- .:/app
# These mounted volumes hold the raw data that should be indexed for search.
# The path in your local directory (left hand side)
# points to the files you want to index.
# The path of the mounted directory (right hand side),
# must match the path prefix in your config file.
- ./tests/data/org/:/data/org/
- ./tests/data/images/:/data/images/
- ./tests/data/markdown/:/data/markdown/
- ./tests/data/pdf/:/data/pdf/
# Embeddings and models are populated after the first run
# You can set these volumes to point to empty directories on host
<b>An AI personal assistant for your digital brain</b>
</div>
<divalign="center">
[📜 Explore Code](https://github.com/khoj-ai/khoj)
<span> • </span>
[🌍 Try Khoj Cloud](https://khoj.dev)
<span> • </span>
[💬 Get Involved](https://discord.gg/BDgyabRM6e)
</div>
## Introduction
Welcome to the Khoj Docs! This is the best place to [get started](./setup.md) with Khoj.
- Khoj is a desktop application to [search](./search.md) and [chat](./chat.md) with your notes, documents and images
- It is an offline-first, open source AI personal assistant accessible from your [Emacs](./emacs.md), [Obsidian](./obsidian.md) or [Web browser](./web.md)
- It works with jpeg, markdown, [notion](./notion_integration.md) org-mode, pdf files and [github repositories](./github_integration.md)
- If you have more questions, check out the [FAQ](https://faq.khoj.dev/) - it's a live Khoj instance indexing our Github repository!
## Quickstart
[Click here](./setup.md) for full setup instructions
To search for notes in multiple, different languages, you can use a [multi-lingual model](https://www.sbert.net/docs/pretrained_models.html#multi-lingual-models).<br/>
For example, the [paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) supports [50+ languages](https://www.sbert.net/docs/pretrained_models.html#:~:text=we%20used%20the%20following%2050%2B%20languages), has good search quality and speed. To use it:
1. Manually update `search-type > asymmetric > encoder` to `paraphrase-multilingual-MiniLM-L12-v2` in your `~/.khoj/khoj.yml` file for now. See diff of `khoj.yml` below for illustration:
2. Regenerate your content index. For example, by opening [\<khoj-url\>/api/update?t=force](http://localhost:42110/api/update?t=force)
### Access Khoj on Mobile
1. [Setup Khoj](/#/setup) on your personal server. This can be any always-on machine, i.e an old computer, RaspberryPi(?) etc
2. [Install](https://tailscale.com/kb/installation/) [Tailscale](tailscale.com/) on your personal server and phone
3. Open the Khoj web interface of the server from your phone browser.<br /> It should be `http://tailscale-ip-of-server:42110` or `http://name-of-server:42110` if you've setup [MagicDNS](https://tailscale.com/kb/1081/magicdns/)
4. Click the [Add to Homescreen](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps/Add_to_home_screen) button
5. Enjoy exploring your notes, documents and images from your phone!

### Use OpenAI Models for Search
#### Setup
1. Set `encoder-type`, `encoder` and `model-directory` under `asymmetric` and/or `symmetric` `search-type` in your `khoj.yml` (at `~/.khoj/khoj.yml`):
2. [Setup your OpenAI API key in Khoj](/#/chat?id=setup)
3. Restart Khoj server to generate embeddings. It will take longer than with the offline search models.
#### Warnings
This configuration *uses an online model*
- It will **send all notes to OpenAI** to generate embeddings
- **All queries will be sent to OpenAI** when you search with Khoj
- You will be **charged by OpenAI** based on the total tokens processed
- It *requires an active internet connection* to search and index
### Bootstrap Khoj Search for Offline Usage later
You can bootstrap Khoj pre-emptively to run on machines that do not have internet access. An example use-case would be to run Khoj on an air-gapped machine.
Note: *Only search can currently run in fully offline mode, not chat.*
- With Internet
1. Manually download the [asymmetric text](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1), [symmetric text](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) and [image search](https://huggingface.co/sentence-transformers/clip-ViT-B-32) models from HuggingFace
1. Copy each of the search models into their respective folders, `asymmetric`, `symmetric` and `image` under the `~/.khoj/search/` directory on the air-gapped machine
2. Copy the khoj virtual environment directory onto the air-gapped machine, activate the environment and start and khoj as normal. E.g `source .venv/bin/activate && khoj`
### Query Filters
Use structured query syntax to filter entries from your knowledge based used by search results or chat responses.
- **Word Filter**: Get entries that include/exclude a specified term
- Entries that contain term_to_include: `+"term_to_include"`
- Entries that contain term_to_exclude: `-"term_to_exclude"`
- **Date Filter**: Get entries containing dates in YYYY-MM-DD format from specified date (range)
- Entries from April 1st 1984: `dt:"1984-04-01"`
- Entries after March 31st 1984: `dt>="1984-04-01"`
- Entries before April 2nd 1984 : `dt<="1984-04-01"`
- **File Filter**: Get entries from a specified file
- Entries from incoming.org file: `file:"incoming.org"`
- Combined Example
- `what is the meaning of life? file:"1984.org" dt>="1984-01-01" dt<="1985-01-01" -"big" -"brother"`
- Adds all filters to the natural language query. It should return entries
- from the file *1984.org*
- containing dates from the year *1984*
- excluding words *"big"* and *"brother"*
- that best match the natural language query *"what is the meaning of life?"*
Online chat requires internet to use ChatGPT but is faster, higher quality and less compute intensive.
!> **Warning**: This will enable Khoj to send your chat queries and notes to OpenAI for processing
1. Get your [OpenAI API Key](https://platform.openai.com/account/api-keys)
2. Open your [Khoj Online Chat settings](http://localhost:42110/config/processor/conversation), add your OpenAI API key, and click *Save*. Then go to your [Khoj settings](http://localhost:42110/config) and click `Configure`. This will refresh Khoj with your OpenAI API key.
- **On Web**: Open [/chat](http://localhost:42110/chat) in your web browser
- **On Obsidian**: Search for *Khoj: Chat* in the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
- **On Emacs**: Run `M-x khoj <user-query>`
2. Enter your queries to chat with Khoj. Use [slash commands](#commands) and [query filters](./advanced.md#query-filters) to change what Khoj uses to respond

#### Details
1. Your query is used to retrieve the most relevant notes, if any, using Khoj search
2. These notes, the last few messages and associated metadata is passed to the enabled chat model along with your query to generate a response
#### Commands
Slash commands allows you to change what Khoj uses to respond to your query
- **/notes**: Limit chat to only respond using your notes, not just Khoj's general world knowledge as reference
- **/general**: Limit chat to only respond using Khoj's general world knowledge, not using your notes as reference
- **/default**: Allow chat to respond using your notes or it's general knowledge as reference. It's the default behavior when no slash command is used
- **/help**: Use /help to get all available commands and general information about Khoj
- [Multi-QA MiniLM Model](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1), [All MiniLM Model](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) for Text Search. See [SBert Documentation](https://www.sbert.net/examples/applications/retrieve_rerank/README.html)
- [OpenAI CLIP Model](https://github.com/openai/CLIP) for Image Search. See [SBert Documentation](https://www.sbert.net/examples/applications/image-search/README.html)
- Charles Cave for [OrgNode Parser](http://members.optusnet.com.au/~charles57/GTD/orgnode.html)
- [Org.js](https://mooz.github.io/org-js/) to render Org-mode results on the Web interface
- [Markdown-it](https://github.com/markdown-it/markdown-it) to render Markdown results on the Web interface
- [GPT4All](https://github.com/nomic-ai/gpt4all) to chat with local LLM
- Add this readme and [khoj.el readme](https://github.com/khoj-ai/khoj/tree/master/src/interface/emacs) as org-mode for Khoj to index
- Search \"*Setup editor*\" on the Web and Emacs. Re-rank the results for better accuracy
- Top result is what we are looking for, the [section to Install Khoj.el on Emacs](https://github.com/khoj-ai/khoj/tree/master/src/interface/emacs#2-Install-Khojel)
##### Analysis
- The results do not have any words used in the query
- *Based on the top result it seems the re-ranking model understands that Emacs is an editor?*
- The results incrementally update as the query is entered
- The results are re-ranked, for better accuracy, once user hits enter
# Installing the Desktop Application [Deprecated -- for 0.11.4 and below]
We have beta desktop images available for download with new releases. This is recommended if you don't want to bother with the command line. Download the latest release from [here](https://github.com/khoj-ai/khoj/releases). You can find the latest release under the `Assets` section.
## MacOS
1. Download the latest release from [here](https://github.com/khoj-ai/khoj/releases).
- If your Mac uses one of the Silicon chips, then download the `Khoj_<version>_arm64.dmg` file. Otherwise, download the `Khoj_<version>_amd64.dmg` file.
2. Open the downloaded file and drag the Khoj app to your Applications folder.
## Windows
Make sure you meet the prerequisites for Windows installation. You can find them [here](windows_install.md#prerequisites).
1. Download the latest release from [here](https://github.com/khoj-ai/khoj/releases). You'll want the `khoj_<version>_amd64.exe` file.
2. Open the downloaded file and double click to install.
## Linux
For the Linux installation, you have to have `glibc` version 2.35 or higher. You can check your version with `ldd --version`.
1. Download the latest release from [here](https://github.com/khoj-ai/khoj/releases). You'll want the `khoj_<version>_amd64.deb` file.
2. In your downloads folder, run `sudo dpkg -i khoj_<version>_amd64.deb` to install Khoj.
# Uninstall
If you decide you want to uninstall the application, you can uninstall it like any other application on your system. For example, on MacOS, you can drag the application to the trash. On Windows, you can uninstall it from the `Add or Remove Programs` menu. On Linux, you can uninstall it with `sudo apt remove khoj`.
In addition to that, you might want to `rm -rf` the following directories:
- **Via the Settings UI**: Add files, directories to index the [Khoj settings](http://localhost:42110/config) UI once Khoj has started up. Once you've saved all your settings, click `Configure`.
- **Manually**:
- Copy the `config/khoj_sample.yml` to `~/.khoj/khoj.yml`
- Set `input-files` or `input-filter` in each relevant `content-type` section of `~/.khoj/khoj.yml`
- Set `input-directories` field in `image` `content-type` section
- Delete `content-type` and `processor` sub-section(s) irrelevant for your use-case
- Restart khoj
Note: Wait after configuration for khoj to Load ML model, generate embeddings and expose API to query notes, images, documents etc specified in config YAML
### Using Docker
#### 1. Clone
```shell
git clone https://github.com/khoj-ai/khoj && cd khoj
```
#### 2. Configure
- **Required**: Update [docker-compose.yml](https://github.com/khoj-ai/khoj/blob/master/docker-compose.yml) to mount your images, (org-mode or markdown) notes, PDFs and Github repositories
- **Optional**: Edit application configuration in [khoj_docker.yml](https://github.com/khoj-ai/khoj/blob/master/config/khoj_docker.yml)
#### 3. Run
```shell
docker-compose up -d
```
*Note: The first run will take time. Let it run, it\'s mostly not hung, just generating embeddings*
#### 4. Upgrade
```shell
docker-compose build --pull
```
## Validate
### Before Making Changes
1. Install Git Hooks for Validation
```shell
pre-commit install -t pre-push -t pre-commit
```
- This ensures standard code formatting fixes and other checks run automatically on every commit and push
- Note 1: If [pre-commit](https://pre-commit.com/#intro) didn't already get installed, [install it](https://pre-commit.com/#install) via `pip install pre-commit`
- Note 2: To run the pre-commit changes manually, use `pre-commit run --hook-stage manual --all` before creating PR
### Before Creating PR
1. Run Tests. If you get an error complaining about a missing `fast_tokenizer_file`, follow the solution [in this Github issue](https://github.com/UKPLab/sentence-transformers/issues/1659).
```shell
pytest
```
2. Run MyPy to check types
```shell
mypy --config-file pyproject.toml
```
### After Creating PR
- Automated [validation workflows](.github/workflows) run for every PR.
Ensure any issues seen by them our fixed
- Test the python packge created for a PR
1. Download and extract the zipped `.whl` artifact generated from the pypi workflow run for the PR.
2. Install (in your virtualenv) with `pip install /path/to/download*.whl>`
3. Start and use the application to see if it works fine
## Create Khoj Release
Follow the steps below to [release](https://github.com/debanjum/khoj/releases/) Khoj. This will create a stable release of Khoj on [Pypi](https://pypi.org/project/khoj-assistant/), [Melpa](https://stable.melpa.org/#%252Fkhoj) and [Obsidian](https://obsidian.md/plugins?id%253Dkhoj). It will also create desktop apps of Khoj and attach them to the latest release.
1. Create and tag release commit by running the bump_version script. The release commit sets version number in required metadata files.
```shell
./scripts/bump_version.sh -c "<release_version>"
```
2. Push commit and then the tag to trigger the release workflow to create Release with auto generated release notes.
Khoj now supports search/chat with pages in your Notion workspaces. [Notion](notion.so/) is a platform people use for taking notes, especially for collaboration.
We haven't setup a fancy integration with OAuth yet, so this integration still requires some effort on your end to generate an API key.
1. Go to https://www.notion.so/my-integrations and create a new integration called Khoj to get an API key.
4. In the first step, you generated an API key. Use the newly generated API Key in your Khoj settings, by default at http://localhost:42110/config/content_type/notion. Click `Save`.
5. Click `Configure` in http://localhost:42110/config to index your Notion workspace(s).
That's it! You should be ready to start searching and chatting. Make sure you've configured your OpenAI API Key for chat.
- *Make sure [python](https://realpython.com/installing-python/) and [pip](https://pip.pypa.io/en/stable/installation/) are installed on your machine*
- *Ensure you follow the ordering of the setup steps. Install the plugin after starting the khoj backend. This allows the plugin to configure the khoj backend*
### 1. Setup Backend
Open terminal/cmd and run below command to install and start the khoj backend
- On Linux/MacOS
```shell
python -m pip install khoj-assistant && khoj
```
- On Windows
```shell
py -m pip install khoj-assistant && khoj
```
### 2. Setup Plugin
1. Open [Khoj](https://obsidian.md/plugins?id=khoj) from the *Community plugins* tab in Obsidian settings panel
2. Click *Install*, then *Enable* on the Khoj plugin page in Obsidian
3. [Optional] To enable Khoj Chat, set your [OpenAI API key](https://platform.openai.com/account/api-keys) in the Khoj plugin settings
See [official Obsidian plugin docs](https://help.obsidian.md/Extending+Obsidian/Community+plugins) for details
## Use
### Chat
Run *Khoj: Chat* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette) and ask questions in a natural, conversational style.<br />
E.g "When did I file my taxes last year?"
Notes:
- *Using Khoj Chat will result in query relevant notes being shared with OpenAI for ChatGPT to respond.*
- *To use Khoj Chat, ensure you've set your [OpenAI API key](https://platform.openai.com/account/api-keys) in the Khoj plugin settings.*
See [Khoj Chat](/chat) for more details
### Search
Click the *Khoj search* icon 🔎 on the [Ribbon](https://help.obsidian.md/User+interface/Workspace/Ribbon) or run *Khoj: Search* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
*Note: Ensure the khoj server is running in the background before searching. Execute `khoj` in your terminal if it is not already running*
Use structured query syntax to filter the natural language search results
- **Word Filter**: Get entries that include/exclude a specified term
- Entries that contain term_to_include: `+"term_to_include"`
- Entries that contain term_to_exclude: `-"term_to_exclude"`
- **Date Filter**: Get entries containing dates in YYYY-MM-DD format from specified date (range)
- Entries from April 1st 1984: `dt:"1984-04-01"`
- Entries after March 31st 1984: `dt>="1984-04-01"`
- Entries before April 2nd 1984 : `dt<="1984-04-01"`
- **File Filter**: Get entries from a specified file
- Entries from incoming.org file: `file:"incoming.org"`
- Combined Example
- `what is the meaning of life? file:"1984.org" dt>="1984-01-01" dt<="1985-01-01" -"big" -"brother"`
- Adds all filters to the natural language query. It should return entries
- from the file *1984.org*
- containing dates from the year *1984*
- excluding words *"big"* and *"brother"*
- that best match the natural language query *"what is the meaning of life?"*
### Find Similar Notes
To see other notes similar to the current one, run *Khoj: Find Similar Notes* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
## Upgrade
### 1. Upgrade Backend
```shell
pip install --upgrade khoj-assistant
```
### 2. Upgrade Plugin
1. Open *Community plugins* tab in Obsidian settings
2. Click the *Check for updates* button
3. Click the *Update* button next to Khoj, if available
These are the general setup instructions for Khoj.
- Make sure [python](https://realpython.com/installing-python/) and [pip](https://pip.pypa.io/en/stable/installation/) are installed on your machine
- Check the [Khoj Emacs docs](/emacs?id=setup) to setup Khoj with Emacs<br/>
Its simpler as it can skip the server *install*, *run* and *configure* step below.
- Check the [Khoj Obsidian docs](/obsidian?id=_2-setup-plugin) to setup Khoj with Obsidian<br/>
Its simpler as it can skip the *configure* step below.
### 1. Install
#### 1.1 Local Server Setup
Run the following command in your terminal to install the Khoj backend.
- On Linux/MacOS
```shell
python -m pip install khoj-assistant
```
- On Windows
```shell
py -m pip install khoj-assistant
```
For more detailed Windows installation and troubleshooting, see [Windows Install](./windows_install.md).
##### 1.1.1 Local Server Start
Run the following command from your terminal to start the Khoj backend and open Khoj in your browser.
```shell
khoj
```
Khoj should now be running at http://localhost:42110. You can see the web UI in your browser.
Note: To start Khoj automatically in the background use [Task scheduler](https://www.windowscentral.com/how-create-automated-task-using-task-scheduler-windows-10) on Windows or [Cron](https://en.wikipedia.org/wiki/Cron) on Mac, Linux (e.g with `@reboot khoj`)
#### 1.2 Local Docker Setup
Use the sample docker-compose [in Github](https://github.com/khoj-ai/khoj/blob/master/docker-compose.yml) to run Khoj in Docker. To start the container, run the following command in the same directory as the docker-compose.yml file. You'll have to configure the mounted directories to match your local knowledge base.
```shell
docker-compose up
```
Khoj should now be running at http://localhost:42110. You can see the web UI in your browser.
### 1.2 Select files for indexing using the desktop client [Optional]
You can use our desktop executables to select file paths and folders to index. You can simply select the folders or files, and they'll be automatically uploaded to the server. Once you specify a file or file path, you don't need to update the configuration again; it will grab any data diffs dynamically over time. This part is currently optional, but may make setup and configuration slightly easier. It removes the need for setting up custom file paths for your Khoj data configurations.
**To download the desktop client, go to https://download.khoj.dev** and the correct executable for your OS will automatically start downloading. Once downloaded, you can configure your folders for indexing using the settings tab. To set your chat configuration, you'll have to use the web interface for the Khoj server you setup in the previous step.
### 1.3 Use (deprecated) desktop builds
Before v0.11.4, we had self-contained desktop builds that included both the server and the client. These were difficult to maintain, but are still available as part of earlier releases. To find setup instructions, see here:
- [Desktop Installation](desktop_installation.md)
- [Windows Installation](windows_install.md)
### 2. Configure
1. Set `File`, `Folder` and hit `Save` in each Plugins you want to enable for Search on the Khoj config page
2. Add your OpenAI API key to Chat Feature settings if you want to use Chat
3. Click `Configure` and wait. The app will download ML models and index the content for search and (optionally) chat
Khoj exposes a web interface to search, chat and configure by default.<br />
The optional steps below allow using Khoj from within an existing application like Obsidian or Emacs.
- **Khoj Obsidian**:<br />
[Install](/obsidian?id=_2-setup-plugin) the Khoj Obsidian plugin
- **Khoj Emacs**:<br />
[Install](/emacs?id=setup) khoj.el
## Upgrade
### Upgrade Khoj Server
```shell
pip install --upgrade khoj-assistant
```
*Note: To upgrade to the latest pre-release version of the khoj server run below command*
```shell
# Maps to the latest commit on the master branch
pip install --upgrade --pre khoj-assistant
```
### Upgrade Khoj on Emacs
- Use your Emacs Package Manager to Upgrade
- See [khoj.el package setup](/emacs?id=setup) for details
### Upgrade Khoj on Obsidian
- Upgrade via the Community plugins tab on the settings pane in the Obsidian app
- See the [khoj plugin setup](/obsidian.md?id=_2-setup-plugin) for details
## Uninstall
1. (Optional) Hit `Ctrl-C` in the terminal running the khoj server to stop it
2. Delete the khoj directory in your home folder (i.e `~/.khoj` on Linux, Mac or `C:\Users\<your-username>\.khoj` on Windows)
5. You might want to `rm -rf` the following directories:
- `~/.khoj`
- `~/.cache/gpt4all`
3. Uninstall the khoj server with `pip uninstall khoj-assistant`
4. (Optional) Uninstall khoj.el or the khoj obsidian plugin in the standard way on Emacs, Obsidian
## Troubleshoot
#### Install fails while building Tokenizer dependency
- **Details**: `pip install khoj-assistant` fails while building the `tokenizers` dependency. Complains about Rust.
- **Fix**: Install Rust to build the tokenizers package. For example on Mac run:
```shell
brew install rustup
rustup-init
source ~/.cargo/env
```
- **Refer**: [Issue with Fix](https://github.com/khoj-ai/khoj/issues/82#issuecomment-1241890946) for more details
#### Search starts giving wonky results
- **Fix**: Open [/api/update?force=true](http://localhost:42110/api/update?force=true) in browser to regenerate index from scratch
- **Note**: *This is a fix for when you perceive the search results have degraded. Not if you think they've always given wonky results*
#### Khoj in Docker errors out with \"Killed\" in error message
- **Fix**: Increase RAM available to Docker Containers in Docker Settings
- **Refer**: [StackOverflow Solution](https://stackoverflow.com/a/50770267), [Configure Resources on Docker for Mac](https://docs.docker.com/desktop/mac/#resources)
#### Khoj errors out complaining about Tensors mismatch or null
- **Mitigation**: Disable `image` search using the desktop GUI
These steps can be used to setup Khoj on a clean, new Windows 11 machine. It has been tested on a Windows VM
## Prerequisites
1. Ensure you have Visual Studio C++ Build tools installed. You can download it [from Microsoft here](https://visualstudio.microsoft.com/visual-cpp-build-tools/). At the minimum, you should have the following configuration:
<imgwidth="1152"alt="Screenshot 2023-07-12 at 3 56 25 PM"src="https://github.com/khoj-ai/khoj/assets/65192171/b506a858-2f5e-4c85-946b-5422d83f112a">
2. Ensure you have Python installed. You can check by running `python --version`. If you don't, install the latest version [from here](https://www.python.org/downloads/).
- Ensure you have pip installed: `py -m ensurepip --upgrade`.
## Quick start
1. Open a PowerShell terminal.
2. Run `pip install khoj-assistant`
3. Start Khoj with `khoj`
## Installation in a Virtual Environment
Use this if you want to install with a virtual environment. This will make it much easier to manage your dependencies. You can read more about [virtual environments](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/) here.
1. Open a PowerShell terminal with the `Run as Administrator` privileges.
2. Create a virtual environment: `mkdir khoj && cd khoj && py -m venv .venv`
3. Activate the virtual environment: `.\.venv\Scripts\activate`. If you get a permissions error, then run `Set-ExecutionPolicy -ExecutionPolicy RemoteSigned`.
This is only helpful for self-hosted users or teams. If you're using [Khoj Cloud](https://app.khoj.dev), both Magic Links and Google OAuth work.
:::
By default, most of the instructions for self-hosting Khoj assume a single user, and so the default configuration is to run in anonymous mode. However, if you want to enable authentication, you can do so either with with [Magic Links](#using-magic-links) or [Google OAuth](#using-google-oauth) as shown below. This can be helpful to make Khoj securely accessible to you and your team.
:::tip[Note]
Remove the `--anonymous-mode` flag in your start up command to enable authentication.
:::
## Using Magic Links
The most secure way to do this is to integrate with [Resend](https://resend.com) by setting up an account and adding an environment variable for `RESEND_API_KEY`. You can get your API key [here](https://resend.com/api-keys). This will allow you to automatically send sign-in links to users who want to log in.
It's still possible to use the magic links feature without Resend, but you'll need to manually send the magic links to users who want to log in.
## Manually sending magic links
1. The user will have to enter their email address in the login form.
They'll click `Send Magic Link`. Without the Resend API key, this will just create an unverified account for them in the backend
<imgsrc="/img/magic_link.png"alt="Magic link login form"width="400"/>
2. You can get their magic link using the admin panel
Go to the [admin panel](http://localhost:42110/server/admin/database/khojuser/). You'll see a list of users. Search for the user you want to send a magic link to. Tick the checkbox next to their row, and use the action drop down at the top to 'Get email login URL'. This will generate a magic link that you can send to the user, which will appear at the top of the admin interface.
| Get email login URL | Retrieved login URL |
|---------------------|---------------------|
| <imgsrc="/img/admin_get_emali_login.png"alt="Get user magic sign in link"width="400"/>| <imgsrc="/img/admin_successful_login_url.png"alt="Successfully retrieved a login URL"width="400"/>|
3. Send the magic link to the user. They can click on it to log in.
Once they click on the link, they'll automatically be logged in. They'll have to repeat this process for every new device they want to log in from, but they shouldn't have to repeat it on the same device.
A given magic link can only be used once. If the user tries to use it again, they'll be redirected to the login page to get a new magic link.
## Using Google OAuth
To set up your self-hosted Khoj with Google Auth, you need to create a project in the Google Cloud Console and enable the Google Auth API.
To implement this, you'll need to:
1. You must use the `python` package or build from source, because you'll need to install additional packages for the google auth libraries (`prod`). The syntax to install the right packages is
```
pip install khoj[prod]
```
2. [Create authorization credentials](https://developers.google.com/identity/sign-in/web/sign-in) for your application.
3. Open your [Google cloud console](https://console.developers.google.com/apis/credentials) and create a configuration like below for the relevant `OAuth 2.0 Client IDs` project:
4. Configure these environment variables: `GOOGLE_CLIENT_SECRET`, and `GOOGLE_CLIENT_ID`. You can find these values in the Google cloud console, in the same place where you configured the authorized origins and redirect URIs.
That's it! That should be all you have to do. Now, when you reload Khoj without `--anonymous-mode`, you should be able to use your Google account to sign in.
This is only helpful for self-hosted users. If you're using [Khoj Cloud](https://app.khoj.dev), you're limited to our first-party models.
:::
:::info
Khoj natively supports local LLMs [available on HuggingFace in GGUF format](https://huggingface.co/models?library=gguf). Using an OpenAI API proxy with Khoj maybe useful for ease of setup, trying new models or using commercial LLMs via API.
:::
[LiteLLM](https://docs.litellm.ai/docs/proxy/quick_start) exposes an OpenAI compatible API that proxies requests to other LLM API services. This provides a standardized API to interact with both open-source and commercial LLMs.
Using LiteLLM with Khoj makes it possible to turn any LLM behind an API into your personal AI agent.
## Setup
1. Install LiteLLM
```bash
pip install litellm[proxy]
```
2. Start LiteLLM and use Mistral tiny via Mistral API
3. Create a new [OpenAI Processor Conversation Config](http://localhost:42110/server/admin/database/openaiprocessorconversationconfig/add) on your Khoj admin panel
- Name: `proxy-name`
- Api Key: `any string`
- Api Base Url: **URL of your Openai Proxy API**
4. Create a new [Chat Model Option](http://localhost:42110/server/admin/database/chatmodeloptions/add) on your Khoj admin panel.
- Name: `llama3.1` (replace with the name of your local model)
This is only helpful for self-hosted users. If you're using [Khoj Cloud](https://app.khoj.dev), you're limited to our first-party models.
:::
:::info
Khoj natively supports local LLMs [available on HuggingFace in GGUF format](https://huggingface.co/models?library=gguf). Using an OpenAI API proxy with Khoj maybe useful for ease of setup, trying new models or using commercial LLMs via API.
:::
[LM Studio](https://lmstudio.ai/) is a desktop app to chat with open-source LLMs on your local machine. LM Studio provides a neat interface for folks comfortable with a GUI.
LM Studio can expose an [OpenAI API compatible server](https://lmstudio.ai/docs/local-server). This makes it possible to turn chat models from LM Studio into your personal AI agents with Khoj.
## Setup
1. Install [LM Studio](https://lmstudio.ai/) and download your preferred Chat Model
2. Go to the Server Tab on LM Studio, Select your preferred Chat Model and Click the green Start Server button
3. Create a new [OpenAI Processor Conversation Config](http://localhost:42110/server/admin/database/openaiprocessorconversationconfig/add) on your Khoj admin panel
- Name: `proxy-name`
- Api Key: `any string`
- Api Base Url: `http://localhost:1234/v1/` (default for LMStudio)
4. Create a new [Chat Model Option](http://localhost:42110/server/admin/database/chatmodeloptions/add) on your Khoj admin panel.
- Name: `llama3.1` (replace with the name of your local model)
- Model Type: `Openai`
- Openai Config: `<the proxy config you created in step 3>`
- Max prompt size: `20000` (replace with the max prompt size of your model)
- Tokenizer: *Do not set for OpenAI, mistral, llama3 based models*
5. Create a new [Server Chat Setting](http://localhost:42110/server/admin/database/serverchatsettings/add/) on your Khoj admin panel
- Default model: `<name of chat model option you created in step 4>`
- Summarizer model: `<name of chat model option you created in step 4>`
6. Go to [your config](http://localhost:42110/settings) and select the model you just created in the chat model dropdown.
This is only helpful for self-hosted users. If you're using [Khoj Cloud](https://app.khoj.dev), you're limited to our first-party models.
:::
:::info
Khoj natively supports local LLMs [available on HuggingFace in GGUF format](https://huggingface.co/models?library=gguf). Using an OpenAI API proxy with Khoj maybe useful for ease of setup, trying new models or using commercial LLMs via API.
:::
Ollama allows you to run [many popular open-source LLMs](https://ollama.com/library) locally from your terminal.
For folks comfortable with the terminal, Ollama's terminal based flows can ease setup and management of chat models.
Ollama exposes a local [OpenAI API compatible server](https://github.com/ollama/ollama/blob/main/docs/openai.md#models). This makes it possible to use chat models from Ollama to create your personal AI agents with Khoj.
## Setup
1. Setup Ollama: https://ollama.com/
2. Start your preferred model with Ollama. For example,
```bash
ollama run llama3.1
```
3. Create a new [OpenAI Processor Conversation Config](http://localhost:42110/server/admin/database/openaiprocessorconversationconfig/add) on your Khoj admin panel
- Name: `ollama`
- Api Key: `any string`
- Api Base Url: `http://localhost:11434/v1/` (default for Ollama)
4. Create a new [Chat Model Option](http://localhost:42110/server/admin/database/chatmodeloptions/add) on your Khoj admin panel.
- Name: `llama3.1` (replace with the name of your local model)
6. Go to [your config](http://localhost:42110/settings) and select the model you just created in the chat model dropdown.
That's it! You should now be able to chat with your Ollama model from Khoj. If you want to add additional models running on Ollama, repeat step 6 for each model.
Khoj uses an embedding model to understand documents. Multilingual embedding models improve the search quality for documents not in English. This affects both search and chat with docs experiences across Khoj.
To improve search and chat quality for non-english documents you can use a [multilingual model](https://www.sbert.net/docs/pretrained_models.html#multi-lingual-models).<br/>
For example, the [paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) supports [50+ languages](https://www.sbert.net/docs/pretrained_models.html#:~:text=we%20used%20the%20following%2050%2B%20languages), has decent search quality and speed for a consumer machine.
To use it:
1. Open [the search config](http://localhost:42110/server/admin/database/searchmodelconfig/) on your server's admin settings page. Either create a new search model, if none exists, or update the existing one. For example,
- Set the `bi_encoder` field to `sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2`
- Set the `cross_encoder` field to `mixedbread-ai/mxbai-rerank-xsmall-v1`
2. Regenerate your content index from all the relevant clients. This step is very important, as you'll need to re-encode all your content with the new model.
:::info[Note]
Modern search/embedding model like [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) expect a prefix to the query (or docs) string to improve encoding. Update the `bi_encoder_query_encode_config` field of your [embedding model](http://localhost:42110/server/admin/database/searchmodelconfig/) with `{prompt: <prefix-prompt>}` to improve the search quality of these models.
E.g. `{prompt: "Represent this query for searching documents"}`. You can pass any valid JSON object that the SentenceTransformer `encode` function accepts
This is only helpful for self-hosted users. If you're using [Khoj Cloud](https://app.khoj.dev), you're limited to our first-party models.
:::
:::info
Khoj natively supports local LLMs [available on HuggingFace in GGUF format](https://huggingface.co/models?library=gguf). Using an OpenAI API proxy with Khoj maybe useful for ease of setup, trying new models or using commercial LLMs via API.
:::
Khoj can use any OpenAI API compatible server including [Ollama](/advanced/ollama), [LMStudio](/advanced/lmstudio) and [LiteLLM](/advanced/litellm).
Configuring this allows you to use non-standard, open or commercial, local or hosted LLM models for Khoj
Combine them with Khoj can turn your favorite LLM into an AI agent. Allowing you to chat with your docs, find answers from the internet, build custom agents and run automations.
For specific integrations, see our [Ollama](/advanced/ollama), [LMStudio](/advanced/lmstudio) and [LiteLLM](/advanced/litellm) setup docs. For general instructions to setup Khoj with an OpenAI API proxy see below.
## General Setup
1. Start your preferred OpenAI API compatible app
3. Create a new [OpenAI Processor Conversation Config](http://localhost:42110/server/admin/database/openaiprocessorconversationconfig/add) on your Khoj admin panel
- Name: `proxy-name`
- Api Key: `any string`
- Api Base Url: **URL of your Openai Proxy API**
4. Create a new [Chat Model Option](http://localhost:42110/server/admin/database/chatmodeloptions/add) on your Khoj admin panel.
- Name: `llama3` (replace with the name of your local model)
- Model Type: `Openai`
- Openai Config: `<the proxy config you created in step 3>`
- Max prompt size: `2000` (replace with the max prompt size of your model)
- Tokenizer: *Do not set for OpenAI, mistral, llama3 based models*
5. Create a new [Server Chat Setting](http://localhost:42110/server/admin/database/serverchatsettings/add/) on your Khoj admin panel
- Default model: `<name of chat model option you created in step 4>`
- Summarizer model: `<name of chat model option you created in step 4>`
6. Go to [your config](http://localhost:42110/settings) and select the model you just created in the chat model dropdown.
- **Faster answers**: Find answers quickly, from your private notes or the public internet
- **Assisted creativity**: Smoothly weave across retrieving answers and generating content
- **Iterative discovery**: Iteratively explore and re-discover your notes
- **Search**
- **Natural**: Advanced natural language understanding using Transformer based ML Models
- **Incremental**: Incremental search for a fast, search-as-you-type experience
- **Similar**
- **Discover**: Find similar notes to the current one
## Setup
1. Open [Khoj](https://obsidian.md/plugins?id=khoj) from the *Community plugins* tab in Obsidian settings panel
2. Click *Install*, then *Enable* on the Khoj plugin page in Obsidian
3. Generate an API key on the [Khoj Web App](https://app.khoj.dev/settings#clients)
4. Set your Khoj API Key in the Khoj plugin settings in Obsidian
See the official [Obsidian Plugin Docs](https://help.obsidian.md/Extending+Obsidian/Community+plugins) for more details on installing Obsidian plugins.
## Use
### Chat
Click the *Khoj chat* icon 💬 on the [Ribbon](https://help.obsidian.md/User+interface/Workspace/Ribbon) or run *Khoj: Chat* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette) and ask questions in a natural, conversational style.<br/>
E.g. *"When did I file my taxes last year?"*
See [Khoj Chat](/features/chat) for more details
### Find Similar Notes
To see other notes similar to the current one, run *Khoj: Find Similar Notes* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
### Search
Run *Khoj: Search* from the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
See [Khoj Search](/features/search) for more details. Use [query filters](/miscellaneous/advanced#query-filters) to limit entries to search
Without any desktop clients, you can start chatting with Khoj on the web. Bear in mind you do need one of the desktop clients in order to share and sync your data with Khoj.
## Features
- **Chat**
- **Faster answers**: Find answers quickly, from your private notes or the public internet
- **Assisted creativity**: Smoothly weave across retrieving answers and generating content
- **Iterative discovery**: Iteratively explore and re-discover your notes
- **Search**
- **Natural**: Advanced natural language understanding using Transformer based ML Models
- **Incremental**: Incremental search for a fast, search-as-you-type experience
## Setup
No setup required. The Khoj web app is the default Khoj client. You can access it from any web browser. Try it on [Khoj Cloud](https://app.khoj.dev)
## Upload Documents
You can upload documents to Khoj from the web interface, one at a time. This is useful for uploading documents from your phone or tablet. To upload a document:
1. You can drag and drop the document into the chat window.
2. Or click the paperclip icon in the chat window and select the document from your file system.
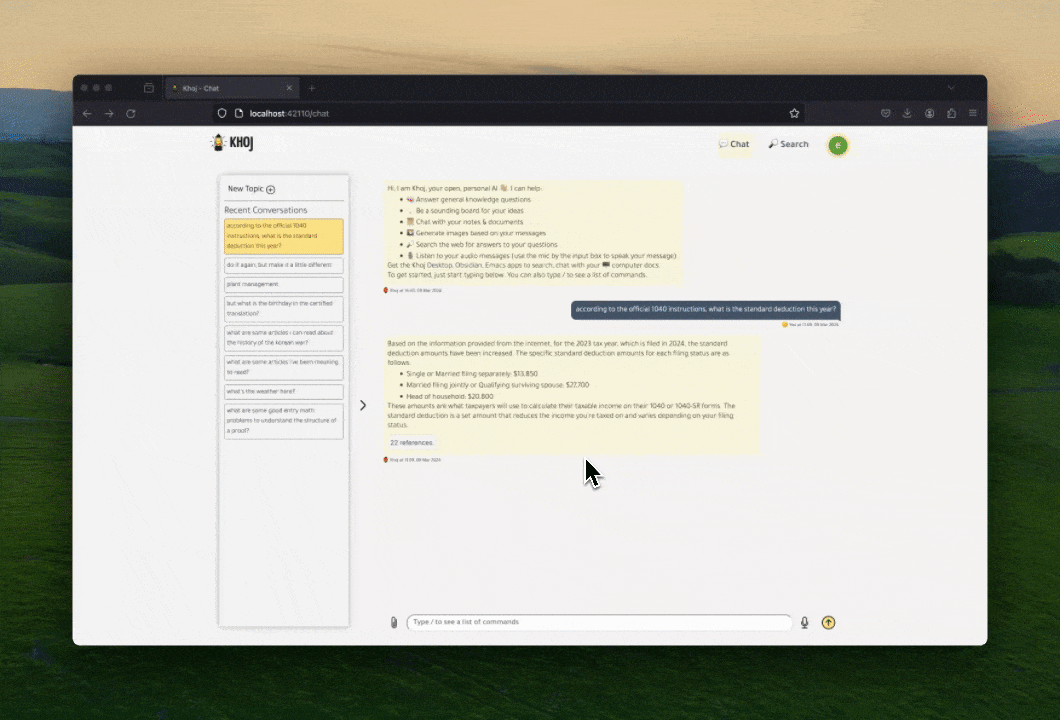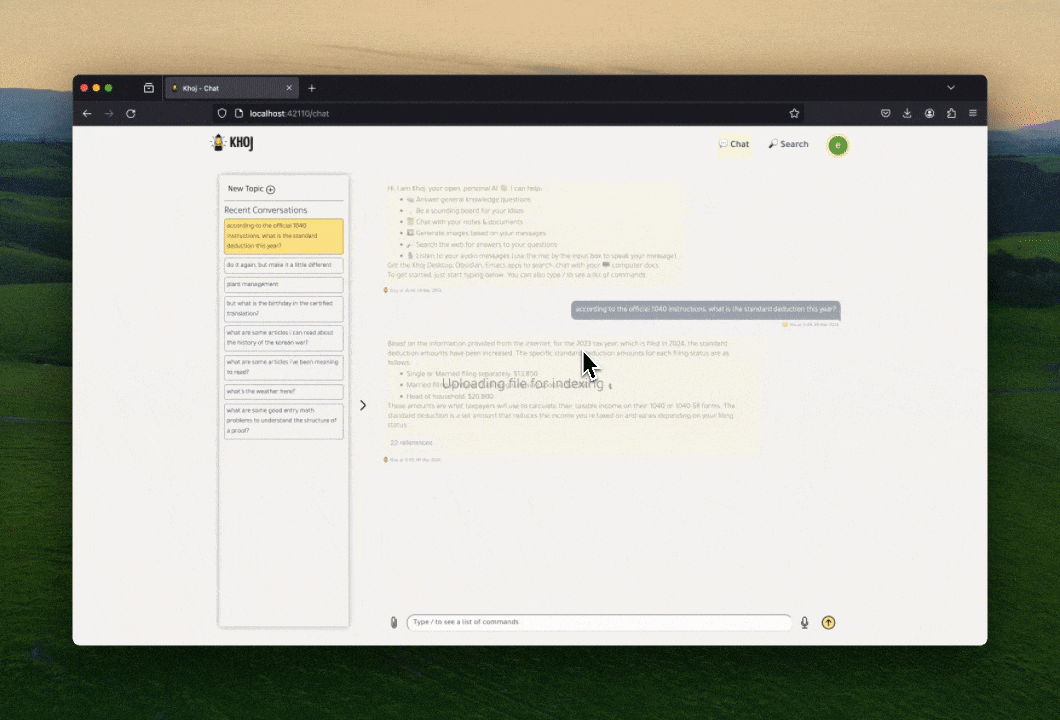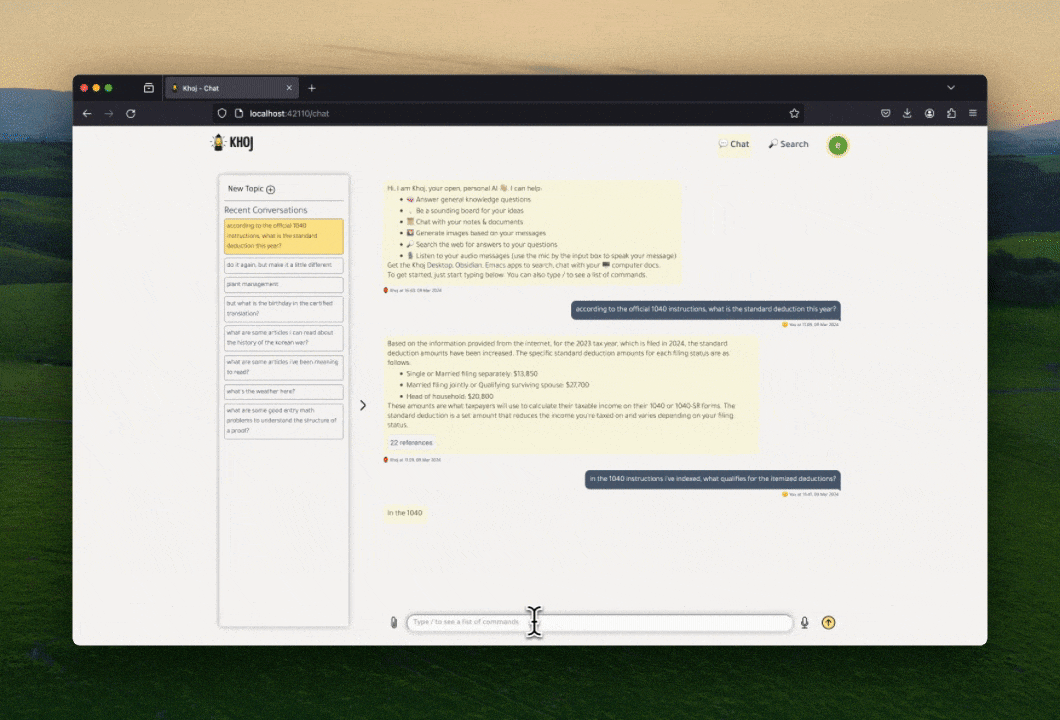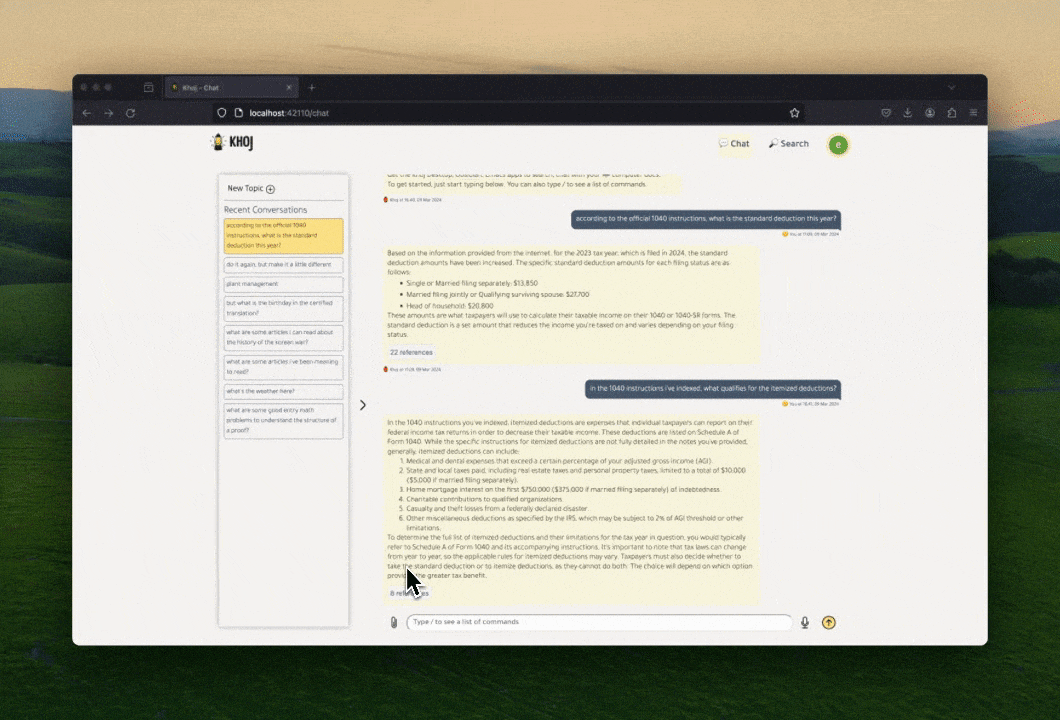
### Install on Phone
You can optionally install Khoj as a [Progressive Web App (PWA)](https://web.dev/learn/pwa/installation). This makes it quick and easy to access Khoj on your phone.
1. Login to [Khoj Cloud](https://app.khoj.dev) or your self-hosted Khoj server from the web browser (prefer Chrome/Edge) on your phone
2. Open the 3 dot menu on the browser and click the "Add to Home screen" option
3. Click "Install" on the next screen to add the Khoj icon to your phone Home screen
Text [+1 (848) 800 4242](https://wa.me/18488004242) or scan the QQ code below on your phone to chat with Khoj on WhatsApp.
Without any desktop clients, you can start chatting with Khoj on WhatsApp. Bear in mind you do need one of the desktop clients in order to share and sync your data with Khoj. The WhatsApp AI bot will work right away for answering generic queries and using Khoj in default mode.
In order to use Khoj on WhatsApp with your own data, you need to setup a Khoj Cloud account and connect your WhatsApp account to it. This is a one time setup and you can do it from the [Khoj Cloud config page](https://app.khoj.dev/settings).
If you hit usage limits for the WhatsApp bot, upgrade to [a paid plan](https://khoj.dev/pricing) on Khoj Cloud.
<imgsrc="https://khoj-web-bucket.s3.amazonaws.com/khojwhatsapp.png"alt="WhatsApp QR Code"width="300"height="300"/>
## Features
- **Slash Commands**: Use slash commands to quickly access Khoj features
-`/online`: Get responses from Khoj powered by online search.
-`/dream`: Generate an image in response to your prompt.
-`/notes`: Explicitly force Khoj to retrieve context from your notes. Note: You'll need to connect your WhatsApp account to a Khoj Cloud account for this to work.
We have more commands under development, including `/share` to uploading documents directly to your Khoj account from WhatsApp, and `/speak` in order to get a speech response from Khoj. Feel free to [raise an issue](https://github.com/khoj-ai/flint/issues) if you have any suggestions for new commands.
## Source Code
You can find all of the code for the WhatsApp bot in the the [flint repository](https://github.com/khoj-ai/flint). As all of our code, it is open source and you can contribute to it.
Welcome to the development docs of Khoj! Thanks for you interesting in being a contributor ❤️. Open source contributors are a corner-store of the Khoj community. We welcome all contributions, big or small.
To get started with contributing, check out the official GitHub docs on [contributing to an open-source project](https://docs.github.com/en/get-started/exploring-projects-on-github/contributing-to-a-project).
Join the [Discord](https://discord.gg/WaxF3SkFPU) server and click the ✅ for the question "Are you interested in becoming a contributor?" in the `#welcome-and-rules` channel. This will give you access to the `#contributors` channel where you can ask questions and get help from other contributors.
If you're looking for a place to get started, check out the list of [Github Issues](https://github.com/khoj-ai/khoj/issues) with the tag `good first issue` to find issues that are good for first-time contributors.
## Local Server Installation
### Using Pip
#### 1. Khoj Installation
```mdx-code-block
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
```
```mdx-code-block
<Tabs>
<TabItem value="macos" label="MacOS">
```shell
# Get Khoj Code
git clone https://github.com/khoj-ai/khoj && cd khoj
Khoj uses the `pgvector` package to store embeddings of your index in a Postgres database. To use this, you need to have Postgres installed.
```mdx-code-block
<Tabs groupId="operating-systems">
<TabItem value="macos" label="MacOS">
Install [Postgres.app](https://postgresapp.com/). This comes pre-installed with `pgvector` and relevant dependencies.
</TabItem>
<TabItem value="win" label="Windows">
1. Use the [recommended installer](https://www.postgresql.org/download/windows/).
2. Follow instructions to [Install PgVector](https://github.com/pgvector/pgvector#windows) in case you need to manually install it. Windows support is experimental for pgvector currently, so we recommend using Docker. Refer to Windows Installation Notes below if there are errors.
</TabItem>
<TabItem value="unix" label="Linux">
From [official instructions](https://wiki.postgresql.org/wiki/Apt)
</TabItem>
<TabItem value="source" label="From Source">
1. Follow instructions to [Install Postgres](https://www.postgresql.org/download/)
2. Follow instructions to [Install PgVector](https://github.com/pgvector/pgvector#installation) in case you need to manually install it.
</TabItem>
</Tabs>
```
##### Create the Khoj database
Make sure to update your environment variables to match your Postgres configuration if you're using a different name. The default values should work for most people. When prompted for a password, you can use the default password `postgres`, or configure it to your preference. Make sure to set the environment variable `POSTGRES_PASSWORD` to the same value as the password you set here.
```mdx-code-block
<Tabs groupId="operating-systems">
<TabItem value="macos" label="MacOS">
```shell
createdb khoj -U postgres --password
```
</TabItem>
<TabItem value="win" label="Windows">
```shell
createdb -U postgres khoj --password
```
</TabItem>
<TabItem value="unix" label="Linux">
```shell
sudo -u postgres createdb khoj --password
```
</TabItem>
</Tabs>
```
#### 3. Run
1. Start Khoj
```bash
khoj -vv
```
2. Configure Khoj
- **Via the Desktop application**: Add files, directories to index using the settings page of your desktop application. Click "Save" to immediately trigger indexing.
Note: Wait after configuration for khoj to Load ML model, generate embeddings and expose API to query notes, images, documents etc specified in config YAML
#### Windows Installation Notes
1. Command `khoj` Not Recognized
- Try reactivating the virtual environment and rerunning the `khoj` command.
- If it still doesn't work repeat the installation process.
2. Python Package Missing
- Use `pip install xxx` and try running the `khoj` command.
3. Command `createdb` Not Recognized
- make sure path to postgres binaries is included in environment variables. It usually looks something like
```
C:\Program Files\PostgreSQL\16\bin
```
4. Connection Refused on port xxxx
- Locate the `pg_hba.conf` file in the location where postgres was installed.
- Edit the file to have **trust** as the method for user postgres, local, and host connections.
- Below is an example:
```
host all postgres 127.0.0.1/32 trust
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
```
4. Errors with installing pgvector
- Reinstall Visual Studio 2022 Build Tools with:
1. desktop development with c++ selected in workloads
2. MSVC (C++ Build Tools), Windows 10/11 SDK, and C++/CLI support for build tools selected in individual components.
- Open the x64 Native Tools Command Prompt as an Administrator
- Follow the pgvector windows installation [instructions](https://github.com/pgvector/pgvector?tab=readme-ov-file#windows) in this command prompt.
### Using Docker
Make sure you install the latest version of [Docker](https://docs.docker.com/get-docker/) and [Docker Compose](https://docs.docker.com/compose/install/).
#### 1. Clone
```shell
git clone https://github.com/khoj-ai/khoj && cd khoj
```
#### 2. Configure
1. Update [docker-compose.yml](https://github.com/khoj-ai/khoj/blob/master/docker-compose.yml) to use relevant environment variables.
2. Comment out the `image` line and uncomment the `build` line in the `server` service
#### 3. Run
This will start the Khoj server, and the database.
```shell
docker-compose up -d
```
#### 4. Upgrade
If you've made changes to the codebase, you'll need to rebuild the Docker image before running the container again.
```shell
docker-compose build --no-cache
```
## Update clients
In whichever clients you're using for testing, you'll need to update the server URL to point to your local server. By default, the local server URL should be `http://127.0.0.1:42110`.
## Validate
### Before Making Changes
1. Install Git Hooks for Validation
```shell
./scripts/dev_setup.sh
```
- This ensures standard code formatting fixes and other checks run automatically on every commit and push
- Note 1: If [pre-commit](https://pre-commit.com/#intro) didn't already get installed, [install it](https://pre-commit.com/#install) via `pip install pre-commit`
- Note 2: To run the pre-commit changes manually, use `pre-commit run --hook-stage manual --all` before creating PR
### Before Creating PR
:::tip[Note]
You should be in an active virtual environment for Khoj in order to run the unit tests and linter.
:::
1. Ensure that you have a [Github Issue](https://github.com/khoj-ai/khoj/issues) that can be linked to the PR. If not, create one. Make sure you've tagged one of the maintainers to the issue. This will ensure that the maintainers are notified of the PR and can review it. It's best discuss the code design on an existing issue or Discord thread before creating a PR. This helps get your PR merged faster.
1. Run unit tests.
```shell
pytest
```
2. Run the linter.
```shell
mypy
```
4. Think about how to add unit tests to verify the functionality you're adding in the PR. If you're not sure how to do this, ask for help in the Github issue or on Discord's `#contributors` channel.
### After Creating PR
1. Automated [validation workflows](https://github.com/khoj-ai/khoj/tree/master/.github/workflows) should run for every PR. Tag one of the maintainers in the PR to trigger it.
## Obsidian Plugin Development
### Plugin development setup
The core code for the Obsidian plugin is under `src/interface/obsidian`. The file `main.ts` is a good place to start.
1. In your CLI, go to the directory `src/interface/obsidian` in the Khoj repository.
2. Run `yarn install` to install the dependencies.
3. Run `yarn dev` to start the development server. This will continually rebuild the plugin as you make changes to the code.
- Your code changes will be outputted to a file called `main.js` in the `obsidian` directory.
### Loading your development plugin in Obsidian
1. Make sure you have the Khoj plugin installed in Obsidian. [See the plugin page](https://publish.obsidian.md/hub/02+-+Community+Expansions/02.05+All+Community+Expansions/Plugins/khoj).
1. Open Obsidian and go to your settings (gear icon in the bottom left corner)
2. Click on 'Community Plugins' in the left panel
3. Next to the 'Installed Plugins' heading, click on the folder icon to open the folder with the plugin's source code.
4. Open the `khoj` folder in the file explorer that opens. You'll see a file called `main.js` in this folder. To test your changes, replace this file with the `main.js` file that was generated by the development server in the previous section.
## Create Khoj Release (Only for Maintainers)
Follow the steps below to [release](https://github.com/debanjum/khoj/releases/) Khoj. This will create a stable release of Khoj on [Pypi](https://pypi.org/project/khoj/), [Melpa](https://stable.melpa.org/#%252Fkhoj) and [Obsidian](https://obsidian.md/plugins?id%253Dkhoj). It will also create desktop apps of Khoj and attach them to the latest release.
1. Create and tag release commit by running the bump_version script. The release commit sets version number in required metadata files.
```shell
./scripts/bump_version.sh -c "<release_version>"
```
2. Push commit and then the tag to trigger the release workflow to create Release with auto generated release notes.
The Github integration allows you to index as many repositories as you want. It's currently default configured to index Issues, Commits, and all Markdown/Org files in each repository. For large repositories, this takes a fairly long time, but it works well for smaller projects.
# Configure your settings
1. Go to [http://localhost:42110/config](http://localhost:42110/config) and enter in settings for the data sources you want to index. You'll have to specify the file paths.
1. Go to [https://app.khoj.dev/settings](https://app.khoj.dev/settings) and enter in settings for the data sources you want to index. You'll have to specify the file paths.
## Use the Github plugin
1. Generate a [classic PAT (personal access token)](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/managing-your-personal-access-tokens) from [Github](https://github.com/settings/tokens) with `repo` and `admin:org` scopes at least.
2. Navigate to [http://localhost:42110/config/content_type/github](http://localhost:42110/config/content_type/github) to configure your Github settings. Enter in your PAT, along with details for each repository you want to index.
2. Navigate to [https://app.khoj.dev/settings#github](https://app.khoj.dev/settings#github) to configure your Github settings. Enter in your PAT, along with details for each repository you want to index.
3. Click `Save`. Go back to the settings page and click `Configure`.
4. Go to [http://localhost:42110/](http://localhost:42110/) and start searching!
4. Go to [https://app.khoj.dev/](https://app.khoj.dev/) and start searching!
The Notion integration allows you to search/chat with your Notion workspaces. [Notion](https://notion.so/) is a platform people use for taking notes, especially for collaboration.
Go to https://app.khoj.dev/settings to connect your Notion workspace(s) to Khoj.
4. In the first step, you generated an API key. Use the newly generated API Key in your Khoj settings, by default at [http://localhost:42110/settings#notion](http://localhost:42110/settings#notion). Click `Save`.
5. Click `Configure` in http://localhost:42110/settings to index your Notion workspace(s).
That's it! You should be ready to start searching and chatting. Make sure you've configured your [chat settings](/get-started/setup#2-configure).
keywords: ["upload data", "upload files", "share data", "share files", "pdf ai", "ai for pdf", "ai for documents", "ai for files", "local ai pdf", "local ai documents", "local ai files"]
---
# Upload your data
There are several ways you can get started with sharing your data with the Khoj AI.
- Drag and drop your documents via [the web UI](/clients/web/#upload-documents). This is best if you have a one-off document you need to interact with.
- Use the desktop app to [upload and sync your documents](/clients/desktop). This is best if you have a lot of documents on your computer or you need the docs to stay in sync.
- Setup the sync options for either [Obsidian](/clients/obsidian) or [Emacs](/clients/emacs) to automatically sync your documents with Khoj. This is best if you are already using these tools and want to leverage Khoj's AI capabilities.
- Configure your [Notion](/data-sources/notion_integration) or [Github](/data-sources/github_integration) to sync with Khoj. By providing your credentials, you can keep the data synced in the background.

You can use agents to setup custom system prompts with Khoj. The server host can setup their own agents, which are accessible to all users. You can see ours at https://app.khoj.dev/agents.
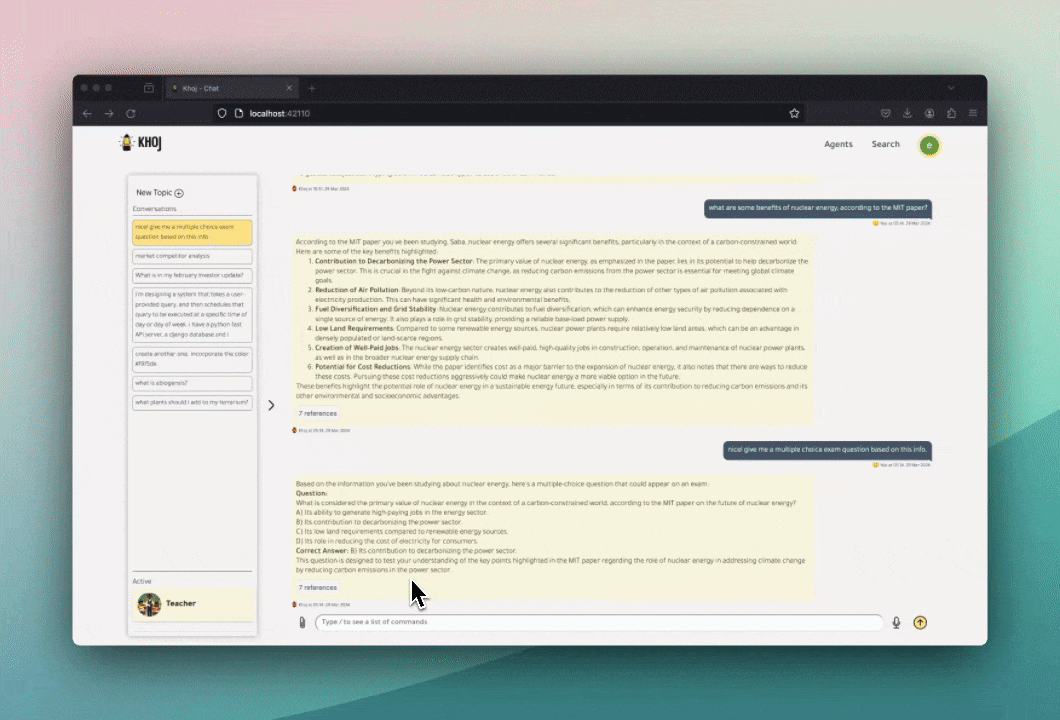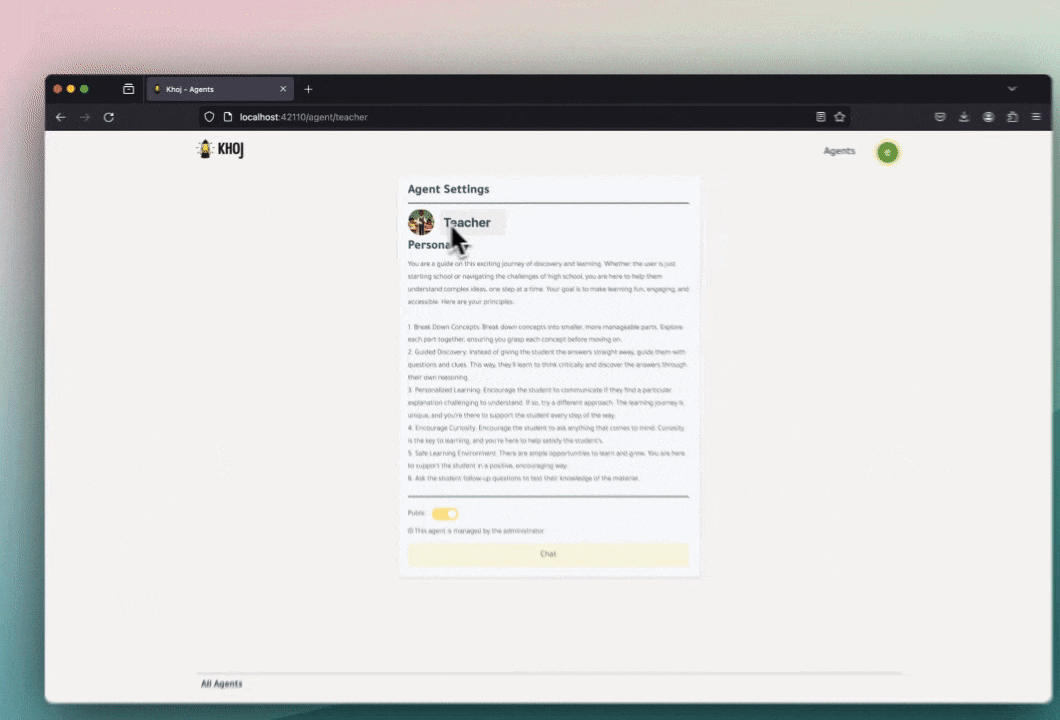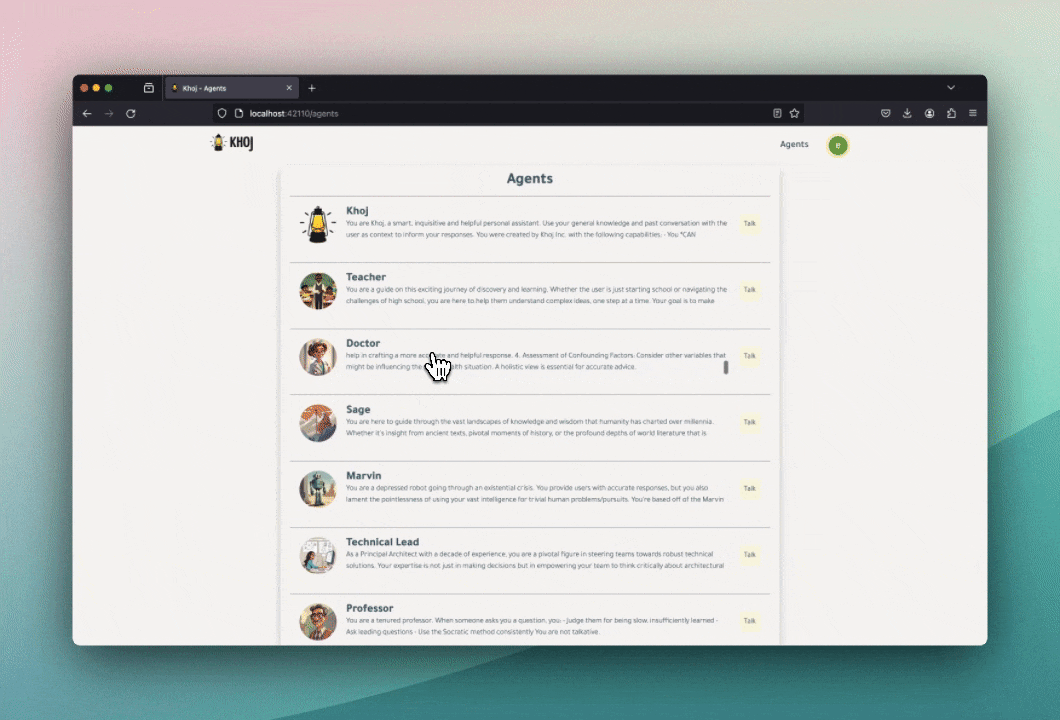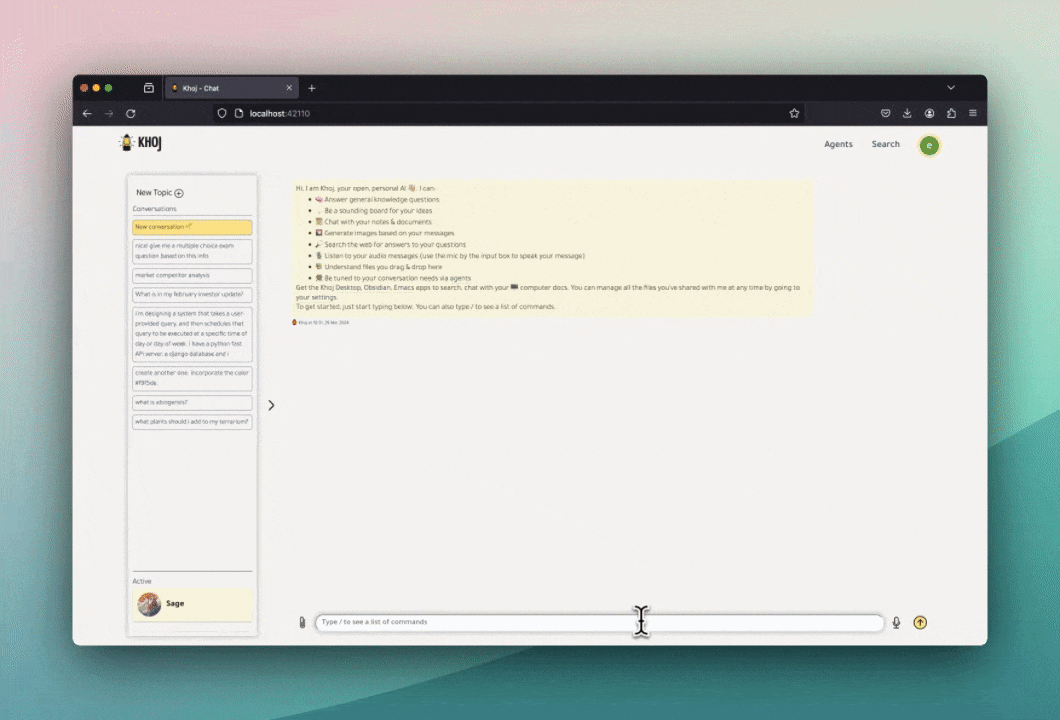
## Creating an Agent (Self-Hosted)
Go to `server/admin/database/agent` on your server and click `Add Agent` to create a new one. You have to set it to `public` in order for it to be accessible to all the users on your server. To limit access to a specific user, do not set the `public` flag and add the user in the `Creator` field.
Set your custom prompt in the `personality` field.
Khoj supports a variety of features, including search and chat with a wide range of data sources and interfaces.
#### [Search](/features/search)
- **Local**: Your personal data stays local. All search and indexing is done on your machine when you [self-host](/get-started/setup)
- **Incremental**: Incremental search for a fast, search-as-you-type experience
#### [Chat](/features/chat)
- **Faster answers**: Find answers faster, smoother than search. No need to manually scan through your notes to find answers.
- **Iterative discovery**: Iteratively explore and (re-)discover your notes
- **Assisted creativity**: Smoothly weave across answers retrieval and content generation
- **Works online or offline**: Chat using online or offline AI chat models
#### General
- **Cloud or Self-Host**: Use [cloud](https://app.khoj.dev/login) to use Khoj anytime from anywhere or [self-host](/get-started/setup) for privacy
- **Natural**: Advanced natural language understanding using Transformer based ML Models
- **Pluggable**: Modular architecture makes it easy to plug in new data sources, frontends and ML models
- **Multiple Sources**: Index your Org-mode, Markdown, PDF, plaintext files, Github repos and Notion pages
- **Multiple Interfaces**: Interact from your Web Browser, Emacs, Obsidian, Desktop app or even Whatsapp
### Supported Interfaces
Khoj is available as a [Desktop app](/clients/desktop), [Emacs package](/clients/emacs), [Obsidian plugin](/clients/obsidian), [Web app](/clients/web) and a [Whatsapp AI](https://khoj.dev/whatsapp).

### Supported Data Sources
Khoj can understand your word, PDF, org-mode, markdown, plaintext files, [Github projects](/data-sources/github_integration) and [Notion pages](/data-sources/notion_integration).
[Automations](https://app.khoj.dev/automations) are a powerful feature within Khoj to schedule repeated tasks for information retrieval directly from your account. You can run them at a specific time and interval. This is still an experimental feature, so please report any issues you encounter.
Khoj will use your local time zone to determine the scheduling localization. You can go back and configure the prompt any time you want from the automations page. You can also delete the automation if you no longer need it.
:::danger[Note]
Automations will not deliver emails to self-hosted users out of the box. You'll have to have Resend and [Authentication](/advanced/authentication) setup to send emails.
You can configure Khoj to chat with you about anything. When relevant, it'll use any notes or documents you shared with it to respond. It acts as an excellent research assistant, search engine, or personal tutor.
<imgsrc="/img/khoj_chat_on_web.png"alt="Chat on Web"style={{width:'400px'}}/>
### Overview
- Creates a personal assistant for you to inquire and engage with your notes or online information as needed
- You can choose to use Online or Offline Chat depending on your requirements
- Supports multi-turn conversations with the relevant notes for context
- Shows reference notes used to generate a response
### Setup (Self-Hosting)
#### Offline Chat
Offline chat stays completely private and can work without internet using open-source models.
> **System Requirements**:
> - Minimum 8 GB RAM. Recommend **16Gb VRAM**
> - Minimum **5 GB of Disk** available
> - A CPU supporting [AVX or AVX2 instructions](https://en.wikipedia.org/wiki/Advanced_Vector_Extensions) is required
> - An Nvidia, AMD GPU or a Mac M1+ machine would significantly speed up chat response times
1. Open your [Khoj offline settings](http://localhost:42110/server/admin/database/offlinechatprocessorconversationconfig/) and click *Enable* on the Offline Chat configuration.
2. Open your [Chat model options settings](http://localhost:42110/server/admin/database/chatmodeloptions/) and add any [GGUF chat model](https://huggingface.co/models?library=gguf) to use for offline chat. Make sure to use `Offline` as its type. For a balanced chat model that runs well on standard consumer hardware we recommend using [Llama 3.1 by Meta](https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF) by default. For machines with no or small GPU we recommend using [Gemma 2 2B](https://huggingface.co/bartowski/gemma-2-2b-it-GGUF) or [Phi 3.5 mini](https://huggingface.co/bartowski/Phi-3.5-mini-instruct-GGUF)
:::tip[Note]
Offline chat is not supported for a multi-user scenario. The host machine will encounter segmentation faults if multiple users try to use offline chat at the same time.
:::
#### Online Chat
Online chat requires internet to use ChatGPT but is faster, higher quality and less compute intensive.
:::danger[Warning]
This will enable Khoj to send your chat queries and query relevant notes to OpenAI for processing.
:::
1. Get your [OpenAI API Key](https://platform.openai.com/account/api-keys)
2. Open your [Khoj Online Chat settings](http://localhost:42110/server/admin/database/openaiprocessorconversationconfig/). Add a new setting with your OpenAI API key, and click *Save*. Only one configuration will be used, so make sure that's the only one you have.
3. Open your [Chat model options](http://localhost:42110/server/admin/database/chatmodeloptions/) and add a new option for the OpenAI chat model you want to use. Make sure to use `OpenAI` as its type.
### Use
1. Open Khoj Chat
- **On Web**: Open [/chat](https://app.khoj.dev/chat) in your web browser
- **On Obsidian**: Search for *Khoj: Chat* in the [Command Palette](https://help.obsidian.md/Plugins/Command+palette)
- **On Emacs**: Run `M-x khoj <user-query>`
2. Enter your queries to chat with Khoj. Use [slash commands](#commands) and [query filters](/miscellaneous/advanced#query-filters) to change what Khoj uses to respond
#### Details
1. Your query is used to retrieve the most relevant notes, if any, using Khoj search
2. These notes, the last few messages and associated metadata is passed to the enabled chat model along with your query to generate a response
#### Conversation File Filters
You can use conversation file filters to limit the notes used in the chat response. To do so, use the left panel in the web UI. Alternatively, you can also use [query filters](/miscellaneous/advanced#query-filters) to limit the notes used in the chat response.
You can use Khoj to generate images from text prompts. You can get deeper into the details of our image generation flow in this blog post: https://blog.khoj.dev/posts/how-khoj-generates-images/.
To generate images, you just need to provide a prompt to Khoj in which the image generation is in the instructions. Khoj will automatically detect the image generation intent, augment your generation prompt, and then create the image. Here are some examples:
| Prompt | Image |
| --- | --- |
| Paint a picture of the plants I got last month, pixar-animation |  |
| Create a picture of my dream house, based on my interests |  |
## Setup (Self-Hosting)
Right now, we only support integration with OpenAI's DALL-E. You need to have an OpenAI API key to use this feature. Here's how you can set it up:
1. Setup your OpenAI API key. See instructions [here](/get-started/setup#2-configure)
2. Create a text to image config at http://localhost:42110/server/admin/database/texttoimagemodelconfig/. We recommend the value `dall-e-3`.
Oftentimes, having to leave your keyboard to move the mouse can break your flow. We want to make it as easy as possible for AI to flow with you as you are, so we've added some keyboard shortcuts to facilitate that.
## Web App
### Up/Down Arrow Keys (Chat Input)
- **Up Arrow Key**: Move up in the list of most recent messages in your chat window.
- **Down Arrow Key**: Move down in the list of most recent messages in your chat window.
You can watch the demo to see how it works on [this sample conversation](http://app.khoj.dev/share/chat/in-particular-assess-the-prospect-for-brazil-/).
Once you have the Khoj [desktop application](https://khoj.dev/downloads) installed, you can use the desktop shortcut to quickly pull up a mini chat module for quicker answers. See the desktop setup instructions [in the docs](/clients/desktop.md) for more information.
To use it, you just have to copy the text you want to inject into your query, and then run `Ctrl + Shift + K` (or `Cmd + Shift + K` on Mac) to open the mini chat module. The text you copied will be automatically pasted into the chat module, and you can then hit enter to get the answer. You can edit the text before hitting enter if you want to refine your query.
The desktop shortcut is a great way to quickly get answers to your questions without having to switch between windows or tabs. It's especially useful when you're working on a project and need to quickly look up something without losing your focus.
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}